『アンサンブル法による機械学習: 基礎とアルゴリズム』を読んでいます。原著の Ensemble Methods: Foundations and Algorithms は Web で閲覧できます。

今回は Random Forest を Go で書いてみました。決定木は Python で書いていたのでその拡張でも良かったのですが, Go の goroutine による並行処理はバギングにおける並列処理に向いているのもあり書いてみました。
アンサンブル法
アンサンブル法は同じ問題を解くために複数の学習器を組み合わせて利用する。大きく逐次アンサンブル法と並列アンサンブル法の2つの枠組みがある。
逐次アンサンブル法の代表的な手法が ブースティング (Boostring) で, 弱学習器を強学習器へと導くことができるアルゴリズムの集まりである。ブースティングの中でも Adaboost は画像認識の分野などで良く知られている。
一方, 並列アンサンブル法の代表的な手法が バギング (Bootstrap AGGregatING) である。 並列アンサンブル法では基本学習器の独立性を考慮することが重要で, 独立な基本学習器を結合することで大きく誤差を減少させることができる。アンサンブルの一般化誤差は Hoeffding の不等式 により与えられる。
バギング
バギングはブートストラップサンプリング (Bootstrap Sampling) と集約 (Aggregating) の2つの要素からなる。
ブートストラップサンプリングは, 基本学習器を学習するために サンプル集合 X から復元抽出により新たなサンプル集合 X’ を作る。サンプル集合 X’ が T 個作られた時に幾つかのデータは一回以上含まれるが, 幾つかのデータは一度も含まれない。含まれる回数は λ=1 のポアソン分布で近似され, 一度も選択されないサンプル (out-of-bag) は全体の 約36.8% となる。
ブートストラップサンプリングはなるべく従属性の低い基本学習器を得るためのもので, T を大きくすることで指数関数的に誤差は少なくなる。
集約は基本学習器の出力を分類に対しては投票 (Voting), 回帰に対しては平均化 (Averaging) を行う。具体的には投票では多数決, 相対多数決, 重みつけ多数決, ソフト多数決など, 平均化では単純平均化, 重みつけ平均化などで集約する。
バギングの性質で重要なのが, バギングは分散を減少させる効果 (variance reduction effect) があり境界を滑らかにさせ, これが不安定な基本学習器 (入力が少し変化するだけ出力が大きく変化する学習器) に対して効果的である点である。[1] 非線形の高い学習器はそもそも不安定なので, 非線形の高い学習器を基本学習器とすることが効果的となる。言い方を変えると, ブートストラップサンプリングでは僅かにしか入力が変わらないことがあるので学習器で多様性を確保しないとバギングの効果が得にくくなってしまう。
Random Forest
Random Forest [Leo Breiman, 2001] は, CART などの決定木のアンサンブル法の代表的な手法。Forest は Ho 1995 によって決定木のアンサンブルであることから名付けられたらしい。
Breiman氏のページ から Random Forest の特徴を引用する。
- It is unexcelled in accuracy among current algorithms.
- It runs efficiently on large data bases.
- It can handle thousands of input variables without variable deletion.
- It gives estimates of what variables are important in the classification.
- It generates an internal unbiased estimate of the generalization error as the forest building progresses.
- It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing.
- It has methods for balancing error in class population unbalanced data sets.
- Generated forests can be saved for future use on other data.
- Prototypes are computed that give information about the relation between the variables and the classification.
- It computes proximities between pairs of cases that can be used in clustering, locating outliers, or (by scaling) give interesting views of the data.
- The capabilities of the above can be extended to unlabeled data, leading to unsupervised clustering, data views and outlier detection.
- It offers an experimental method for detecting variable interactions.
英語に自信はないけど和訳してみる。
- 現在 (=当時) のアルゴリズムの中では精度について比類がない
- 大規模データで効率的に実行できる
- 数千の変数を削除せずに処理できる
- 変数重要度を推定できる
- 学習が進むにつれて一般化誤差の不偏推定量を生成する
- データが欠損している場合に精度を維持したまま欠損値を推定する有効な方法を有する
- 不均衡データセットの誤差をバランスさせるための方法を有する
- 生成されたモデルは保存できる
- 変数と分類の関係についての情報を与えるプロトタイプが計算される
- クラスタリングや外れ値検出などデータの興味深い視点を与える近傍性を計算する
- ラベル無しデータに拡張することで, 教師無しクラスタリング、外れ値検出に繋げられる
- 変数間の交互作用を検出するための実験的方法を提供する
それなりの精度を出せて変数重要度も推定でき, 勾配降下法などで必要な事前のデータ標準化・正規化を必要としないため, とりあえず Random Forest となることが多い印象がある。 一方, パラメータチューニングは必要で, Decision Forests for Classification,Regression, Density Estimation, Manifold Learning and Semi-Supervised Learning [Criminisi 2011] では木の深さの最大値 D を大きくした場合, 集約により個々の木の過学習を緩和することができるが完全には解決できないため, 最適な D は慎重に選択した方が良いとしている。
Random Features
Random Forest はバギングに加えて個々の木の構築においてランダムな特徴選択を行なっている点が特徴的である。これは決定木の分割選択のステップで特徴の部分集合をランダムに選択する。
ランダム特徴選択の特性について論文中の 3. Using Random Features で以下のように言及されている。
- i)Its accuracy is as good as Adaboost and sometimes better.
- ii)It’s relatively robust to outliers and noise.
- iii)It’s faster than bagging or boosting.
- iv)It gives useful internal estimates of error, strength, correlation and variable importance.
- v)It’s simple and easily parallelized.
再び和訳。
- i)精度は Adaboost に匹敵し時にはより良い
- ii)外れ値とノイズに対して比較的ロバスト
- iii)bagging や boosting より高速
- iv)誤差、強さ、相関および変動重要度についての役立つ内部評価を与える
- v)シンプルで並列化が容易
理解できた範囲だと, 精度に関しては単純なバギングだと決定木間の相関が高くなりアンサンブルの効果が薄れ精度が出にくいが, ランダム特徴選択により多様な決定木を生成できるため相関が低くなりアンサンブルの効果が大きくなる。また, 特に全体の特徴数が多い場合に部分的な特徴数 K に絞ることで個々の決定木の構築が速くなる。 (K が全体の特徴数と等しい場合, 従来の決定木と同じ)
ちなみに論文の著者によって提案されている K の値は特徴数の対数をとった値である。
Go で Random Forest を書いてみた
全体的に Forest -> Tree -> Node の流れで処理を落としていく実装。
Forest を構築している部分が以下。バギングの各ランダム木は独立して生成できるため goroutine による並行処理で非同期にランダム木を生成する。同期は channel で行い, 全てのランダム木からメッセージを受け取るまでブロックする。ランダム木の成長は再帰的に行う。
// Build a forest of trees from the training set.
func (f *Forest) Build(features [][]float64, labels []float64) *Forest {
f.Trees = make([]*Tree, f.estimators)
done := make(chan bool)
for i := 0; i < f.estimators; i++ {
go func(n int) {
f.Trees[n] = NewTree(f.bagger.task, f.maxDepth)
subFeatures, subLabels := f.bagger.BootstrapSampling(features, labels)
f.Trees[n].Build(subFeatures, subLabels)
done <- true
}(i)
}
for i := 1; i <= f.estimators; i++ {
<-done
}
return f
}
簡単な動作確認として本に出てくる人工データセットを真似た以下のデータ (n = 500) で 訓練:テスト を約 7:3 に分割し決定木との比較を行なった。
ただし, out-of-bag error はまだ実装してなく他の実装との速度比較もしていない。

比較の決定木は R の {rpart} で作成した。
> model <- rpart(Y ~ X1 + X2, data = df.train, method = "class")
> print(model)
n= 343
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 343 151 1 (0.440233236 0.559766764)
2) X2< -0.5782425 100 16 -1 (0.840000000 0.160000000)
4) X1< 1.082618 90 8 -1 (0.911111111 0.088888889) *
5) X1>=1.082618 10 2 1 (0.200000000 0.800000000) *
3) X2>=-0.5782425 243 67 1 (0.275720165 0.724279835)
6) X1< -0.4064311 79 28 -1 (0.645569620 0.354430380)
12) X2< 1.113712 70 19 -1 (0.728571429 0.271428571)
24) X1< -0.8144771 40 4 -1 (0.900000000 0.100000000) *
25) X1>=-0.8144771 30 15 -1 (0.500000000 0.500000000)
50) X2< 0.1671435 14 3 -1 (0.785714286 0.214285714) *
51) X2>=0.1671435 16 4 1 (0.250000000 0.750000000) *
13) X2>=1.113712 9 0 1 (0.000000000 1.000000000) *
7) X1>=-0.4064311 164 16 1 (0.097560976 0.902439024)
14) X2< 0.0641908 56 15 1 (0.267857143 0.732142857)
28) X1< -0.06947993 12 2 -1 (0.833333333 0.166666667) *
29) X1>=-0.06947993 44 5 1 (0.113636364 0.886363636) *
15) X2>=0.0641908 108 1 1 (0.009259259 0.990740741) *
> pred.train <- predict(model, df.train, type = "class")
> table(df.train$Y, pred.train)
pred.train
-1 1
-1 139 12
1 17 175
> pred.test <- predict(model, df.test, type = "class")
> table(df.test$Y, pred.test)
pred.test
-1 1
-1 52 16
1 12 77
決定木の訓練データに対する結果は以下で accuracy は 0.915 (314/343) となった。 また, テストデータに対する accuracy は 0.821 (129/157) となった。
 Random Forest のパラメータは ランダム木の数を 30, ランダム特徴数を 1, 各木の深さの最大値を 7 として実験した。
Random Forest のパラメータは ランダム木の数を 30, ランダム特徴数を 1, 各木の深さの最大値を 7 として実験した。
Random Forest の訓練データに対する結果は以下で accuracy は 0.985 (338/343) となった。 また, テストデータに対する accuracy は 0.866 (136/157) となった。
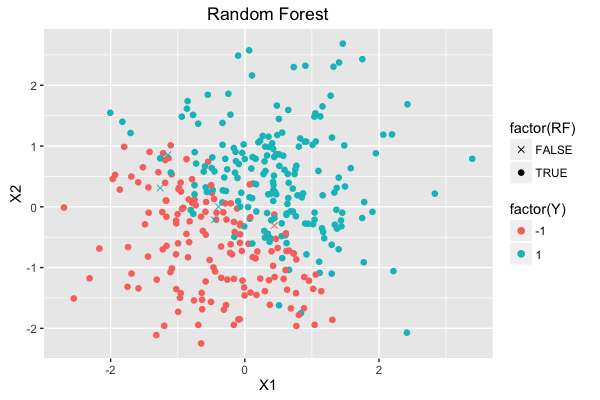
R の {randomForest} も加えた全ての結果が以下。 パラメータチューニングをすれば多少結果も前後すると思う。
| training accuracy | test accuracy | |
|---|---|---|
| DecisionTree (R, {rpart}) | 0.915 | 0.821 |
| RandomForest (R, {randomForest}) | 1.000 | 0.879 |
| RandomForest (Go) | 0.985 | 0.866 |
Code は GitHub に置いた。
おわりに
今回は Go で Random Forest を書いてみました。 Go の BLAS ベースの行列演算ライブラリ Gonum/matrix は NumPy のように普及するまで至ってない印象で依存して良いかなど判断に迷う部分もありました。
参考書籍ではこの他に, 異常検出におけるアンサンブル (3.5.4)や 機械学習コンペでも有名な学習による結合を行うスタッキング (4.4), 個々の基本学習器を部分的に選択するアンサンブル枝刈り (6章), クラスタリングアンサンブル (7章) なども扱っていて中々読み応えがあります。
[1] Analyzing bagging [Bühlmann and Yu 2002]
[2] [Freideman and Hall 2007] ではバギングは高次の項の分散を減少させるが1次の項については影響がないとしている。
[3] Hoeffding の不等式
[4] Ensemble Methods: Foundations and Algorithms
[5] iForest
[6] SCiForest
[7] KAGGLE ENSEMBLING GUIDE