前に書いた【MSGD】Goで確率的勾配降下法を書いてみた【gonum/matrix】 の続きで goroutine で MSGD (Mini-batch Stochastic Gradient Descent)を並行処理化してみました。
参考にさせて頂いた書籍は, オンライン機械学習 (機械学習プロフェッショナルシリーズ)です。

確率的勾配降下法の並列化
前回は Minibatch に分割して Minibatch単位で パラメータを更新する MSGD を書いた。
確率的勾配降下法 (に限らずオンライン学習に関する最適化手法?) の並列化について, 大まかに下記の3つのアプローチがある。
- Bulk Synchronous Parallel(BSP) : 各プロセスが1回同期するたびに全体を同期する
- Parallel SGD : 各プロセスで学習し, 最後に1度だけパラメータベクトルの平均を計算する [1]
- Iterative Parameter Mixture (ISP) : 何回かのパラメータ更新の後に, プロセス間で同期する。上記2つの中間的手法
Parallel SGD は同期のオーバーヘッドが小さく, BSPはパラメータのバラつきが小さく, ISPはバランス重視なのが特徴。
BSPの一般化として, Stale Synchronous Parallel (SSP) [2]があり, パラメータが大きく離れないように stalenessという定数により制約を与える。これをクラスタ数など環境に合わせて調整することで, 同期のオーバーヘッドを抑えながら精度を保って並列学習ができる。SSPは制約を踏まえることで理論的な保証を与えることができる点も利点。
詳しくは参考書籍を見ていただくとして, 今回は簡単そうな Parallel SGD を goroutine を使って書いて実験してみた。
確率的勾配降下法の goroutine による並行化
当初 Go で書こうと思った理由のひとつに goroutine で並行処理させたいというのがあった。
Go では go func() で簡単に並行処理を行うことができ, Chanelを用いて goroutine間で通信ができる。
今回は下記3つの 実行時間の比較をしてみる。
- goroutineなしSGD
- goroutineなしMini-batch SGD
- goroutineありMini-batch SGD
共通して, 2つの正規分布から N=10,000 のサンプルを生成し, (μ, σ) はそれぞれ (0, 1)と (5, 1)として, labelとして y = 0, y = 1をとしている。また, SGD の処理とは直接関係ない サンプルの生成や グラフの描画・保存部分は計測対象から外している。
以降, Go 1.7.4 で動作確認していて, 行列演算には gonum/matrixを使っている。
goroutineなしMSGDが下記。
// Minibatch SGD (minibatch stochastic gradient descent)
for i := 0; i < N/batch_size; i++ {
x_part, y_part := grad.DivideData(data, i*batch_size, batch_size)
// batch processing
w_grad, b_grad := g.Grad(x_part, y_part, batch_size)
// Update parameters
g.Weight[0] -= eta * w_grad[0]
g.Weight[1] -= eta * w_grad[1]
g.Intercept -= eta * b_grad[0]
yhat := g.CalcLikeLihood(x, N)
err_sum := 0.0
for i := 0; i < len(yhat); i++ {
err_sum += math.Abs(y[i] - yhat[i])
}
g.Errors = append(g.Errors, err_sum/float64(len(yhat)))
}
batch_sizeを 1 とすると 1行ずつ(ランダムに)取り出して計算する SGD と同じとなる。goroutineなしSGDの結果。
$ go run norm-sequential.go
length-of-data = 10000 batch-size = 1
weight = [2.0476605141036415 1.6041310664873036] intercept = -8.733287985345507
final error = 0.0023539070634504005
31212.125653 ms
次に, batch_sizeを 10 とした goroutineなしMSGDの結果。MSGDにするだけで大分速くなる。
$ go run norm-sequential.go
length-of-data = 10000 batch-size = 10
weight = [1.3207115597551597 1.0808973348687458] intercept = -5.162778403705652
final error = 0.01175294743423504
2922.810345 ms
4つの goroutine で同じサイズになるように Data を分割して, それぞれの goroutine が 別々に Minibatch SGDを行う。この処理を worker関数 に切り出した goroutineありMSGDが下記。
func worker(N, goroutines, batch_size int, data, x *mat64.Dense, y []float64) <-chan *grad.Grad {
receiver := make(chan *grad.Grad)
for i := 0; i < goroutines; i++ {
go func(i int) {
eta := 0.2
g := grad.NewGrad(eta)
offset := i * N / goroutines
// Minibatch SGD (minibatch stochastic gradient descent)
for j := 0; j < N/(goroutines*batch_size); j++ {
x_part, y_part := grad.DivideData(data, j*batch_size+offset, batch_size)
w_grad, b_grad := g.Grad(x_part, y_part, batch_size)
// Update parameters
g.Weight[0] -= eta * w_grad[0]
g.Weight[1] -= eta * w_grad[1]
g.Intercept -= eta * b_grad[0]
yhat := g.CalcLikeLihood(x, N)
err_sum := 0.0
for k := 0; k < len(yhat); k++ {
err_sum += math.Abs(y[k] - yhat[k])
}
g.Errors = append(g.Errors, err_sum/float64(len(yhat)))
}
fmt.Println("goroutine =", i, "batch-size =", batch_size)
fmt.Println("weight =", g.Weight, "b =", g.Intercept)
fmt.Println("final error =", g.Errors[N/(goroutines*batch_size)-1], "\n")
receiver <- g
}(i)
}
return receiver
}
Channel を使うことで goroutine 間で Message-Passing することができるので, 非同期で動いている goroutine から受け取った パラメータを保持しておき全て出揃ったタイミングで 平均値を計算し最終的なパラメータとしている。
// Concurrent processing with multiple workers
receiver := worker(N, goroutines, batch_size, data, x, y)
for i := 0; i < goroutines; i++ {
r := <-receiver
w1 = append(w1, r.Weight[0])
w2 = append(w2, r.Weight[1])
b = append(b, r.Intercept)
}
// mean of each parameters
weights := []float64{grad.Mean(w1), grad.Mean(w2)}
intercept := grad.Mean(b)
fmt.Println("mean of weights =", weights, "mean of intercept =", intercept)
goroutineありMSGDの結果。
$ go run norm-goroutine.go
Your machine has 4 cores
goroutine = 3 batch-size = 10
weight = [0.8568881326005832 0.9594250210107855] b = -3.397460056554312
final error = 0.033202413093255806
goroutine = 1 batch-size = 10
weight = [0.9708144234062192 0.5771582780124764] b = -3.4170497792455423
final error = 0.037412139639221645
goroutine = 2 batch-size = 10
weight = [0.8060100160357799 0.9688809183747621] b = -3.375866075985577
final error = 0.0337096268381657
goroutine = 0 batch-size = 10
weight = [0.9504827291514886 0.8037499086226864] b = -3.3324324328409265
final error = 0.03477794978278259
mean of weights = [0.8960488252985177 0.8273035315051775] mean of intercept = -3.3807020861565893
1807.352476 ms
gorutine (4 Cores) で動かすことで 2922 ms から 1807 ms と 3割-4割程度の短縮となった。何度か計測してみたが, ほぼ同程度となった。
gorutineなしMSGDの分離超平面が以下。

gorutineありMSGDの分離超平面。やや負例寄りに線が引かれているように見える。
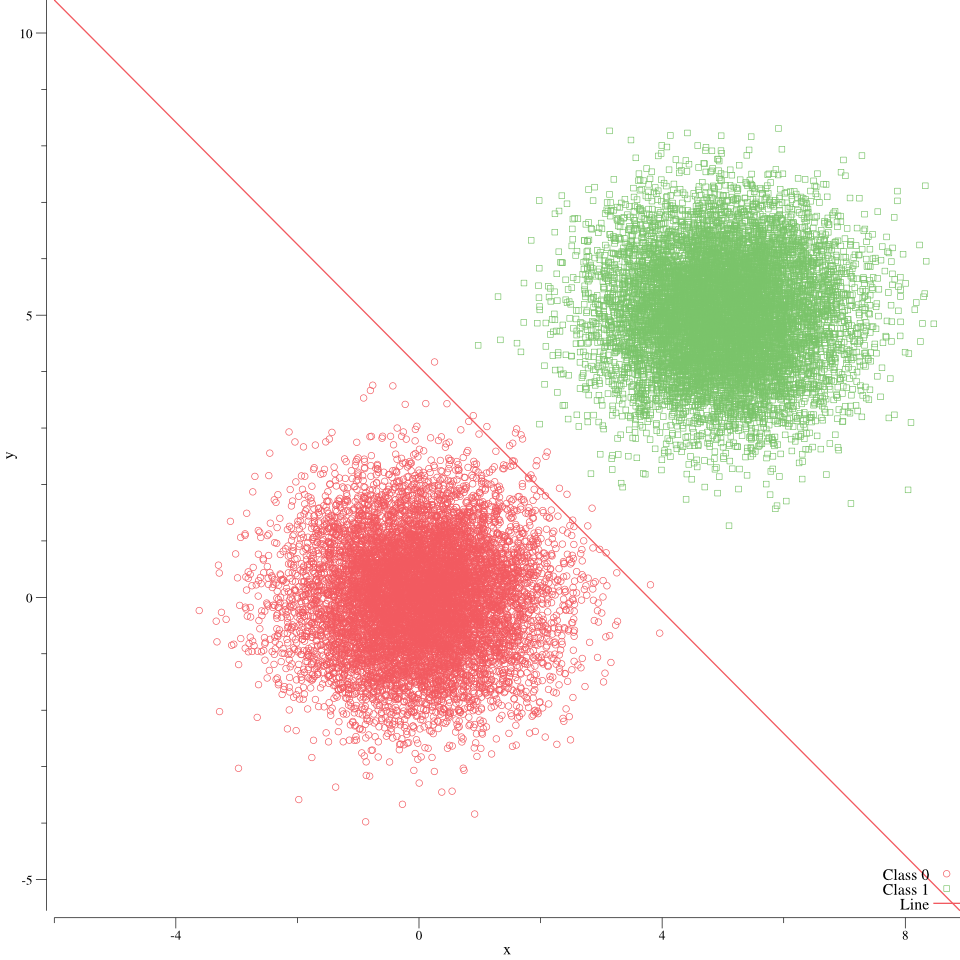
最終的な損失は, パラメータを引き継いでいる gorutineなしMSGDの方が小さかったが, gorutineありMSGDでもそこそこ分離できているとも取れる。
Codeは Github に置いた。
[1] Parallelized Stochastic Gradient Descent
[2] More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server