前回の {dlm} を用いた状態空間モデルを Stan でも試してみます。
今回も備忘録になります。環境は macOS 10.12, R 3.3.1, rstan 2.16.2 です。
はじめに
前回も使った架空の日次PVデータに曜日 (0-6), 広告費, イベント (長期休暇) を表す変数を追加する。
広告費は pv 増加要因, 長期休暇は pv 減少要因の想定とする。
> head(df)
X date pv week ad vacation
1 1 2016/9/1 490 0 0 0
2 2 2016/9/2 450 1 0 0
3 3 2016/9/3 176 2 0 0
4 4 2016/9/4 158 3 0 0
5 5 2016/9/5 440 4 0 0
6 6 2016/9/6 546 5 0 0

最初に前回の季節要素のあるトレンドモデルに似たモデルを作り, 続いて広告効果, イベント効果の項を追加する。
季節要素のある二次トレンドモデル
季節要素 (週効果) のある二次トレンドモデル。簡略化した表現の分解モデルを以下とする。

二次のトレンドモデルは, t 時点と t-1 時点の差が t-1 時点 と t-2 時点の差に大体等しいことで表す。

また, 週効果は各曜日の効果の和をゼロとする。
Stan コードは以下。
data {
int<lower=1> N;
int<lower=0, upper="6"> week_day[N];
vector<lower=0>[N] y;
}
parameters {
vector[N] trend;
vector[6] s_raw;
vector[N] ar;
real c_ar[2];
real<lower=0> s_trend;
real<lower=0> s_ar;
real<lower=0> s_r;
}
transformed parameters {
vector[7] s;
vector[N] week;
vector[N] y_mu;
s[1:6] = s_raw;
s[7] = -sum(s_raw);
for(i in 1:N)
week[i] = s[week_day[i]+1];
y_mu = trend + week + ar;
}
model {
s_trend ~ normal(0, 10);
s_ar ~ normal(0, 10);
s_r ~ normal(0, 20);
trend[3:N] ~ normal(2*trend[2:N-1] - trend[1:N-2], s_trend);
ar[3:N] ~ normal(c_ar[1]*ar[2:N-1] + c_ar[2]*ar[1:N-2], s_ar);
y ~ normal(y_mu, s_r);
}
各パラメータの Rhat は概ね 1.1 以下で収束している様子だけど s_ar は工夫の余地が残った。
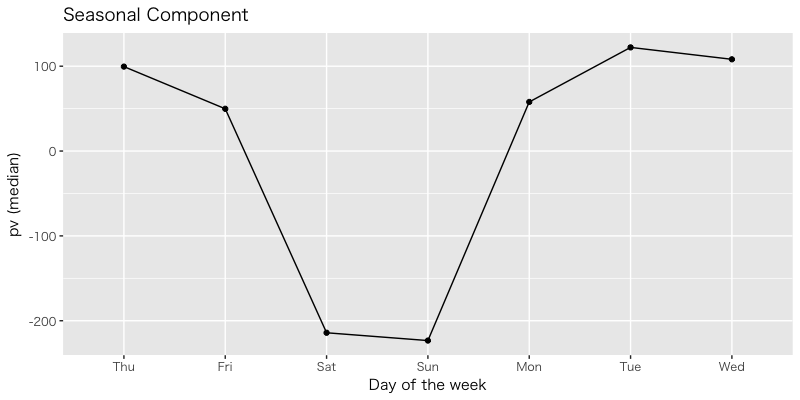
週効果のパラメータの中央値は以下で, 前回の {dlm} の推定値とほぼ同じとなった。
> df.week
week week.med
1 Thu 99.52395
2 Fri 49.80439
3 Sat -214.16421
4 Sun -223.37538
5 Mon 57.86294
6 Tue 122.16797
7 Wed 108.13716
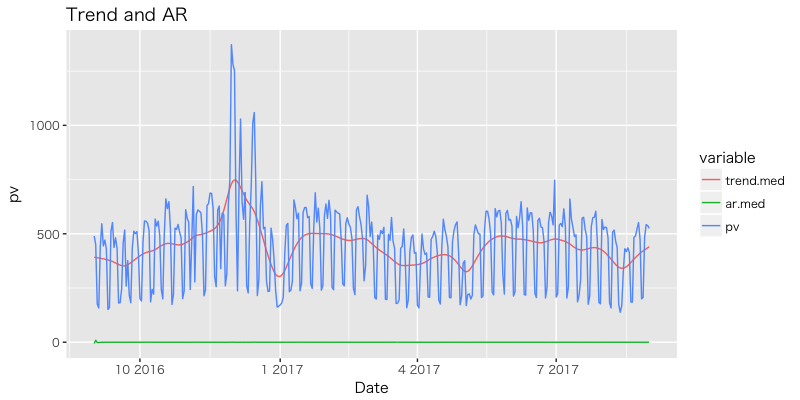
{dlm} のトレンドモデルと比較すると, トレンドはより短期的に変動している。(二次トレンドモデルなので致し方なし)
イベント効果の導入
最初のモデルに広告効果, イベント効果を表す項を追加する。

Stanコードは以下。
data {
int<lower=1> N;
int<lower=0, upper="6"> week_day[N];
vector<lower=0>[N] y;
vector<lower=0, upper="100">[N] advertisement;
vector<lower=0, upper="1">[N] vacation;
}
parameters {
vector[N] trend;
vector[6] s_raw;
vector[N] ar;
real c_ar[2];
real<lower=-100, upper="100"> c_ad;
real<lower=-100, upper="100"> c_vacation;
real<lower=0> s_trend;
real<lower=0> s_ar;
real<lower=0> s_r;
}
transformed parameters {
vector[7] s;
vector[N] week;
vector[N] y_mu;
vector[N] ad;
vector[N] va;
s[1:6] = s_raw;
s[7] = -sum(s_raw);
for(i in 1:N)
week[i] = s[week_day[i]+1];
ad = c_ad * advertisement;
va = c_vacation * vacation;
y_mu = trend + week + ad + va + ar;
}
model {
s_trend ~ normal(0, 10);
s_ar ~ normal(0, 10);
s_r ~ normal(0, 20);
trend[3:N] ~ normal(2*trend[2:N-1] - trend[1:N-2], s_trend);
ar[3:N] ~ normal(c_ar[1]*ar[2:N-1] + c_ar[2]*ar[1:N-2], s_ar);
y ~ normal(y_mu, s_r);
}
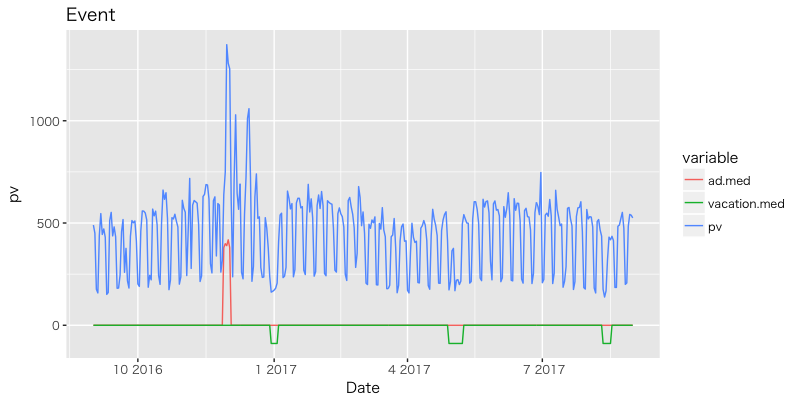
広告効果, イベント効果のパラメータの中央値を図示。
架空のデータではあるが pv に対して広告投下は 400 程度の増加効果, 長期休暇中は 90 程度の減少効果がありそうだ。
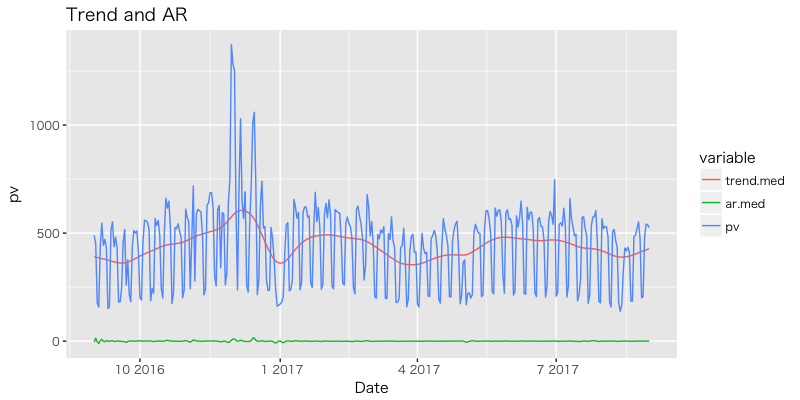
広告効果, イベント効果の導入でトレンドがやや滑らかになった。
データとコードは GitHub に置いた。
おわりに
久しぶりに Stan を使ったのですが, vector を使うと劇的に高速化し驚きました。参考書籍は『StanとRでベイズ統計モデリング』です。特に状態空間モデルについては 12章 時間や空間を扱うモデル をご覧ください。

[1] RStanで『予測にいかす統計モデリングの基本』の売上データの分析をする
[2] RStanのおさらいをしながら読む 岩波DS 1
[3] R grepl Function