今回は KDD ’19 に採択された論文 『Deep Anomaly Detection with Deviation Networks』[Pang et al. 2019] を読みましたので備忘録を残しておきます。
関連研究と課題
異常検知は以下をはじめとして様々な領域で使われている。
- サイバーセキュリティ分野でのネットワーク攻撃の検出
- ファイナンス分野での不正取引の検出
- ヘルスケア分野での疾患の検出
これらの領域の異常検知では特徴の複雑な関係を捉える必要があり, 異常検出分野での深層学習の利用は, 主に複雑な関係を捉えるための特徴の表現学習に焦点が当てられてきた。
しかし, 『Deep Learning for Anomaly Detection: A Survey 』(サーベイ論文) でも指摘されているように, これまで提案されてきた手法の多くは特徴抽出と異常検知が別々に最適化されるために学習の効率が悪く, 性能も suboptimal に留まってしまうという課題があった。
具体的には, AE での入力特徴の低次元の表現学習や GANs での潜在空間での敵対的学習により得られる reconstruction error を使って異常スコアを定義する方法があるが, 多くは表現学習と異常検知が別々に最適化される two-step approach である。この点については, REPEN [1] や Deep SVDD [2], OCNN [3] といった最近の研究では, 従来の異常のスコアリングを目的関数に組み込み統合する方法が提案されている。
また, 異常検知の応用領域では大量のラベルデータを取得することはコストが非常に高いため, 実用的な多くの手法は主に教師なし学習であるが, 事前知識を持たないためノイズや関心の対象ではないデータに反応し易いといった教師なし学習に共通した問題に繋がる可能性がある。
DEVIATION NETWORKS
この問題の潜在的な解決策として, 本論文では少数のラベル付き異常データを事前知識として活用する E2E の Deviation Networks (DevNet) を提案している。DevNet は少数のラベル付き異常データ (e.g. 数十程度) と事前知識を使って, 正常なデータから異常スコアの偏差を学習する。
ラベル異常付きデータとは, 正常に検知されたネットワークへの侵入記録や, 顧客から銀行に報告されたクレジットカードの不正利用の履歴などである。
Problem Statement
訓練データとして X = {x1, x2, · · · , xN , xN +1, xN +2, · · · , xN +K } with x_i ∈ R が与えられる。U = {x1, x2, · · · , xN } はラベルなしデータ, K = {xN +1, xN +2, · · · , xN +K } は少数のラベル付きの異常データとする。X は U と K の和集合で, U と K の積集合は空集合とする。また, データサイズはラベルなしデータのサイズ N に対してラベル付きの異常データのサイズ K は非常に少ない, つまり K << N とする。
目標は X に対して異常スコアを返す, 異常スコアリング関数 ϕ : X → R を学習することである。
Architecture
DevNet のアーキテクチャは以下のように示される。
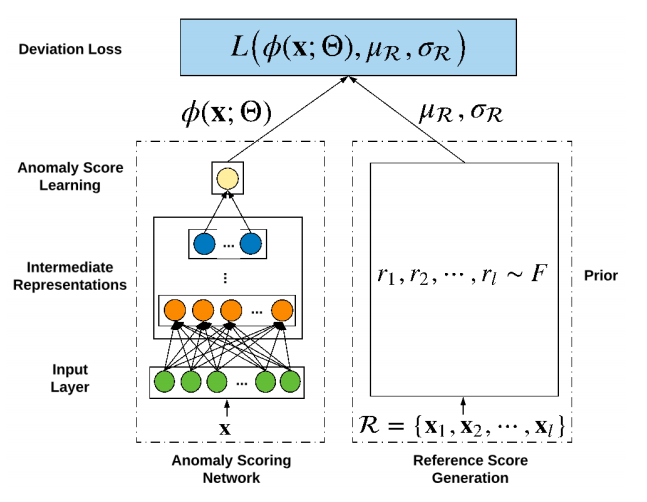
- 左側の anomaly scoring network (i.e. ϕ) は入力 x に対して中間表現を経て異常スコア (スカラー値) を出力する。
- 異常スコアの学習をガイドするため, 右側の reference score generator は参照スコア µ_R (スカラー値) を生成する。µ_R は正常なデータの事前確率 F からランダムに選択された l 個の異常スコア {r1, 2, …, r_l} の平均。(prior-driven approach)
- ϕ(x) と 参照スコア µ_R, 標準偏差 σ_R の3つを共に deviation loss function L に入力しθを勾配降下法で最適化する。
deviation を Z-Score として以下のように定義する。

全体の損失関数 (deviation loss function) L は dev(x) を用いて以下とする。ここで, x が異常な場合は y=1, 正常な場合は y=0, また a は Z-Score の信頼区間パラメータとする。

正常データを F の周辺に強制し, 異常なデータは統計的に F から遠くに押し出すように最適化される。これによって, 表現学習が異常データから正常なデータを識別できるようになる。言い換えると, 少数のラベル付き異常データと異常スコアの事前知識を使って, 正常な振る舞いの高レベルな抽象化を学習し, オブジェクトの振る舞いがこの抽象化から大幅に逸脱している限り, 入力データに大きな異常スコアを割り当てることができる。
事前確率をどのように定めるかは課題となるが,『Interpreting and Unifying Outlier Scores』では複数のデータセットで実験を行い, ガウス分布 N(μ, σ^2) が異常スコアによく適合することを示しているようである。
The DevNet Algorithm
DevNet のアルゴリズムは以下となる。

実験
本論文の実験は, 以下の計9つの real-world データセットで行っている。

donors, fraud, backdoor, URL, thyroid の5つのデータセットには実際の異常が含まれており, その他の4つのデータセットには”意味的”な異常が含まれている。”意味的”というのは, 例えば census ではデータに含まれる約6%の高所得者を便宜上, 異常として扱っている。
Performance
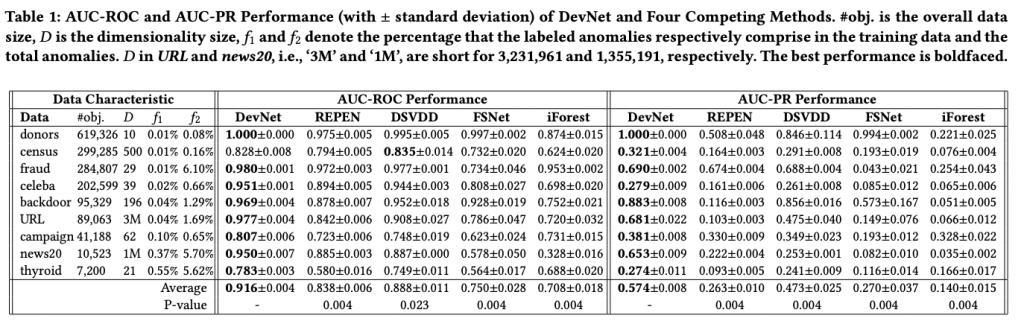
評価指標は AUC-ROC と AUC-PR で, 比較手法は REPEN, adaptive Deep SVDD (DSVDD), prototypical networks (FSNet), iForest の4つである。
結果は以下で, DevNet がほとんどのデータセットにおいて比較手法の性能を上回っている。
Data Efficiency
また, 以下の2つの問いに答えるために, ラベル付き異常データの数を 5 から 120 と変化させる実験を行っている。(anomaly contamination の割合は 2% で固定)
- 他の深層学習による手法と比較して, DevNet はデータ効率性 (Data Efficiency) は良いのか
- 深層学習による手法は, 教師なし学習である iForest (baseline) と比較してラベル付き異常データから得られた情報により性能はどの程度, 改善されるのか
結果は以下で, 深層学習による手法は概ねラベル付き異常データの数が増えると AUC-PR が改善する傾向がある。また, DevNet は最もデータ効率性が高く安定的である。
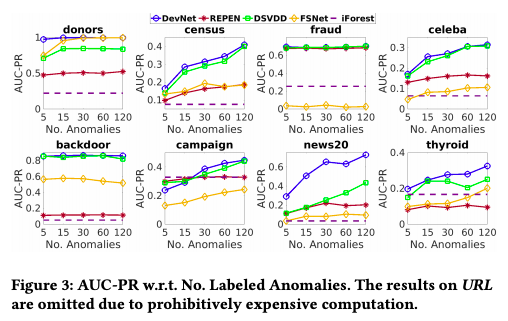
FSNet の census と backdoor データセットに対する結果のように深層学習による手法でも, ラベル付き異常データが増えても検出性能があまり改善しない場合があるが, これは異なる性質の異常が混ざっているため最適化時に情報が競合しているかもしれないと述べられている。
おわりに
今回は, 深層学習ベースの異常検知手法として, 既存の表現学習と異常検出の最適化を別々に行う two-step approach でなく, 少数のラベル付き異常データを用いて異常スコアの最適化を行う DevNet を提案した 『Deep Anomaly Detection with Deviation Networks』 の概要を紹介しました。
[1] Learning Representations of Ultrahigh-dimensional Data for Random Distance-based Outlier Detection[2] Deep one-class classification
[3] Anomaly Detection using One-Class Neural Networks