K近傍法
k近傍法 (k-nearest neighbor algorithm) は, 特徴空間上で最も近い距離にある訓練データに基づいて分類/回帰を行う手法であり, 直感的にもわかりやすいパターン認識手法です。
最短近傍法は与えられた未知データに対して一番近い訓練データのクラスに属しているだろうというのが基本的な考えで, 特徴空間で距離が近い順から k 個選択し多数決でクラスを推定するのが kNN法 です。一般的にはユークリッド距離が使われます。
一方, 訓練データにノイズが多かったり k を小さくした場合に精度が下がりやすい特徴があります。特徴空間が高次元になるとデータ間の距離が遠くなるため, 予め有用な特徴の見当がつく場合は特徴選択を行う方が良いです。また, 基本的に特徴空間全てを保持するためメモリ負荷が高くなります。
kNN in R
{class} パッケージを使います。kNN() は以下です。
knn(train, test, cl, k = 1, l = 0, prob = FALSE, use.all = TRUE)
Wineデータセットを使います。
Wine データセットは3つの異なる品種のワインを化学的な分析により, 13の特徴量で線形分離されたサンプルサイズ 178 のデータセットです。
3つの各クラスの前半 30 個を訓練データに使用し, 残りを評価に使います。
library(class)
library(dplyr)
# wine <- data(wine)
wine <- read.csv("data/wine.data", header = FALSE)
colnames(wine) <- c("class", "Alcohol", "Malic Acid", "Ash", "Alcalinity of Ash",
"Magnesium", "Total Phenols", "Flavanoids", "Nonflavanoid Phenols",
"Proanthocyanins", "Color Intensity", "Hue",
"0D280/OD315 of Diluted Wines", "Proline")
wine$class <- as.factor(wine$class)
c1 <- wine %>%
filter(class == 1)
c2 <- wine %>%
filter(class == 2)
c3 <- wine %>%
filter(class == 3)
t_size <- 30
train_X <- rbind(c1[1:t_size,-1], c2[1:t_size,-1], c3[1:t_size,-1])
train_y <- c(c1$class[1:t_size], c2$class[1:t_size], c3$class[1:t_size])
test_X <- rbind(c1[(t_size+1):nrow(c1),-1], c2[(t_size+1):nrow(c2),-1], c3[(t_size+1):nrow(c3),-1])
test_y <- c(c1$class[(t_size+1):nrow(c1)], c2$class[(t_size+1):nrow(c2)], c3$class[(t_size+1):nrow(c3)])
# knn
res <- knn(train_X, test = test_X, cl = train_y, k = 3, prob = TRUE)
table(res)
# res
# 1 2 3
# 28 43 17
table(test_y)
# test_y
# 1 2 3
# 29 41 18
# accuracy
sum(res == test_y)/length(test_y)
# [1] 0.7045455
k = 3 で正解率は 0.705 でした。
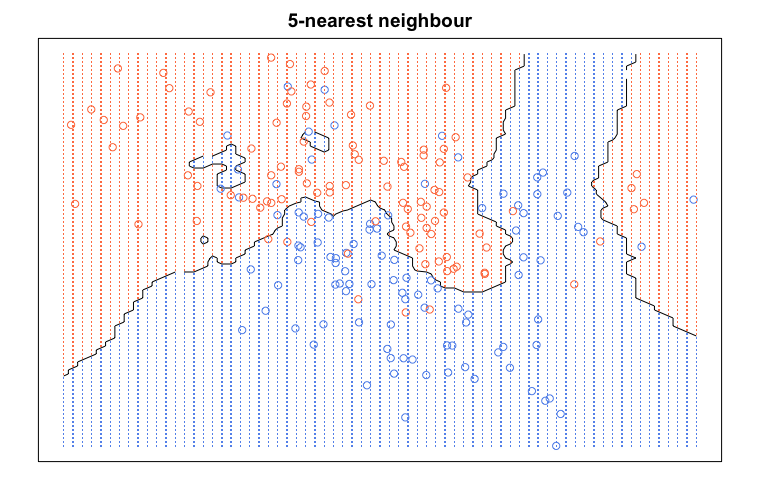
Visualization
{ElemStatLearn} パッケージの mixture.example データセットを使い kNN の分離平面を可視化してみます。mixture.example データセットは 2 クラスで各 100 サンプルを含んでいます
df <- ElemStatLearn::mixture.example
train_X <- df$x
train_y <- df$y
test_X <- df$xnew
# kNN
mod5 <- knn(train_X, test = test_X, cl = train_y , k = 5, prob = TRUE)
prob <- attr(mod5, "prob")
prob5 <- matrix(ifelse(mod5 == "1", prob, 1 - prob),
length(df$px1),
length(df$px2))
# plot
col_y <- ifelse(train_y == 1, "coral", "cornflowerblue")
col_pred <- ifelse(prob5 > 0.5, "coral", "cornflowerblue")
par(mar = rep(2,4))
contour(df$px1, df$px2, prob5,
levels = 0.5, labels = "",
xlab = "", ylab = "", main = "5-nearest neighbour",
axes = FALSE)
points(train_X, col = col_y)
gd <- expand.grid(x = df$px1, y = df$px2)
points(gd,pch = ".", cex = 1.2, col = col_pred)
box()
参考書籍は『はじめてのパターン認識』です。

[1] はじめてのパターン認識 第5章 k最近傍法(k_nn法)
[2] kNNによるデータ分類
[3] Using the k-Nearest Neighbors Algorithm in R