最近公開された Fashion-MNIST データセットに対して t-SNE を試しました。環境は以下です。
- macOS 10.12.6
- CPU Core i5 1.6 GHz
- メモリ DDR3 8GB
- Python 2.7.13
t-SNE
SNE (Stochastic Neighbor Embedding) [1] は非線形次元削減の手法。サンプル間の類似度を条件付き確率で表現する。例えば, ある点 i から別の点 j との類似性は i を中心とするガウス分布で定義される i の近傍の中で見つかる j の条件付き確率 p(j|i) とする。全てのサンプルについて p(j|i) を求めた上で, 高次元空間上での i, j 間の類似度を pij とする。次元削減前後での条件付き確率の誤差を最小化 (なるべく確率分布が一致) するように勾配法で最適化する。分布間の近さを表す尺度として KLダイバージェンスを用いる。 SNE は LRE (Linear Relational Embedding) [2] の特殊な場合。
t-SNE (t-Distributed Stochastic Neighbor Embedding) [3] は SNE の改良版でガウス分布ではなく 自由度1 の t分布 を用いる。裾の長い t分布 を用いることで, 初期に離れてしまった点が潜在的なクラスタを形成しにくくなる Crowding problem を緩和する。
Barnes-Hut-SNE [4] は t-SNE の Barnes-Hut Algorithm を用いた高速版で, t-SNE が O(N^2) であるのに対して O(N log N) となる。一方, その分やや精度は下がる。
Fashion-MNIST
Fashion-MNIST はドイツのECサイト Zalando が公開しているデータセット。10クラスのラベルを持つ 28×28 サイズのグレースケール画像。
訓練データに 60,000 画像, テストデータには 10,000 画像が含まれている。各クラスは以下となっている。
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
0-9のクラスを3行 (90画像) ずつ並べた図が以下。
![]()
ちなみにローカル環境の TensorFlow CNN で 2000 steps x 13 = 26000 steps 回して Test Accuracy が 0.86 となった。
Python で t-SNE
今回はまず scikit-learn の PCA, TSNE と, Python BHTSNE を試した。
Fashion-MNIST 10,000 画像 での計算時間を測ったところ以下となった。 (sklearn t-SNE の method は barnes_hut を指定)
| 計算時間(sec) | |
|---|---|
| PCA (sklearn) | 1 |
| t-SNE (sklearn) | 265 |
| t-SNE (Python BHTSNE) | 181 |
sklearn は Python BHTSNE と比べて約1.4倍遅かった。これは sklearn がおそらく純な Python 実装, Python BHTSNE は著者が公開している c++ 実装 bhtsne の wrapper 部分を Cython で書いていることが原因のひとつと思われる。
以降, Barnes-Hut-SNE は Python BHTSNE を使う。
Barnes-Hut-SNE のパラメータ perplexity は局所的特徴と大域的特徴のどちらを優先させるかのバランスのパラメータで適切な値はデータの密度に依存し, 密度の高いデータには大きな値を設定する。論文中 [3] や著者のサイトでは一般的に 5 ~ 50 程度としている。 また, 後の論文 [4] では 30.0 に設定されており公式実装のデフォルトパラメータにもなっている。
DEFAULT_NO_DIMS = 2
DEFAULT_PERPLEXITY = 30.0
DEFAULT_THETA = 0.5
EMPTY_SEED = -1
perplexity を 5, 30, 50, 500 と変化させてみた。 サンプルサイズ N は 10,000, Barnes-Hut の度合いを表すパラメータ theta は 0.5 で共通。 (thetaは 1 に近いほど速くなるが精度は落ちる。 一般的には 0.2 – 0.8 に設定するらしい。)
perplexity = 5
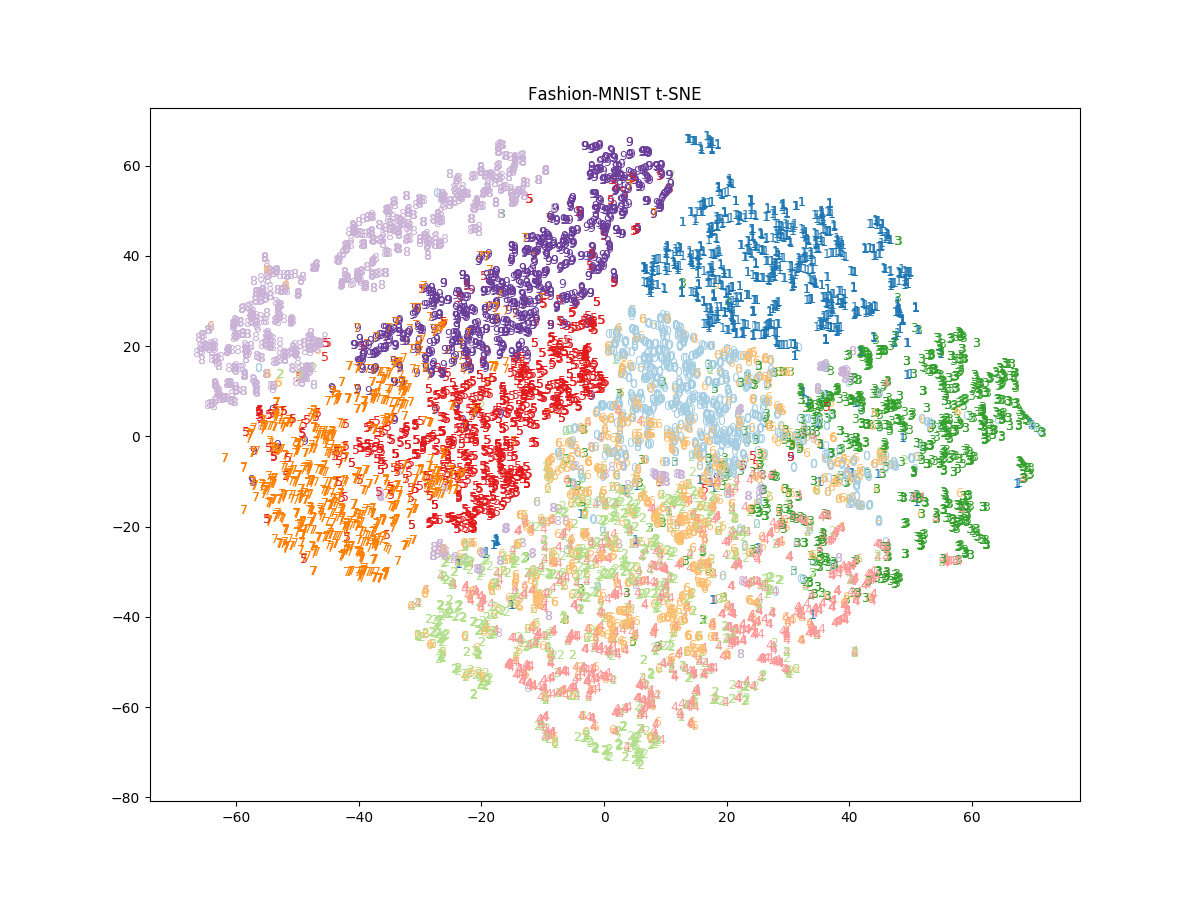
perplexity = 30
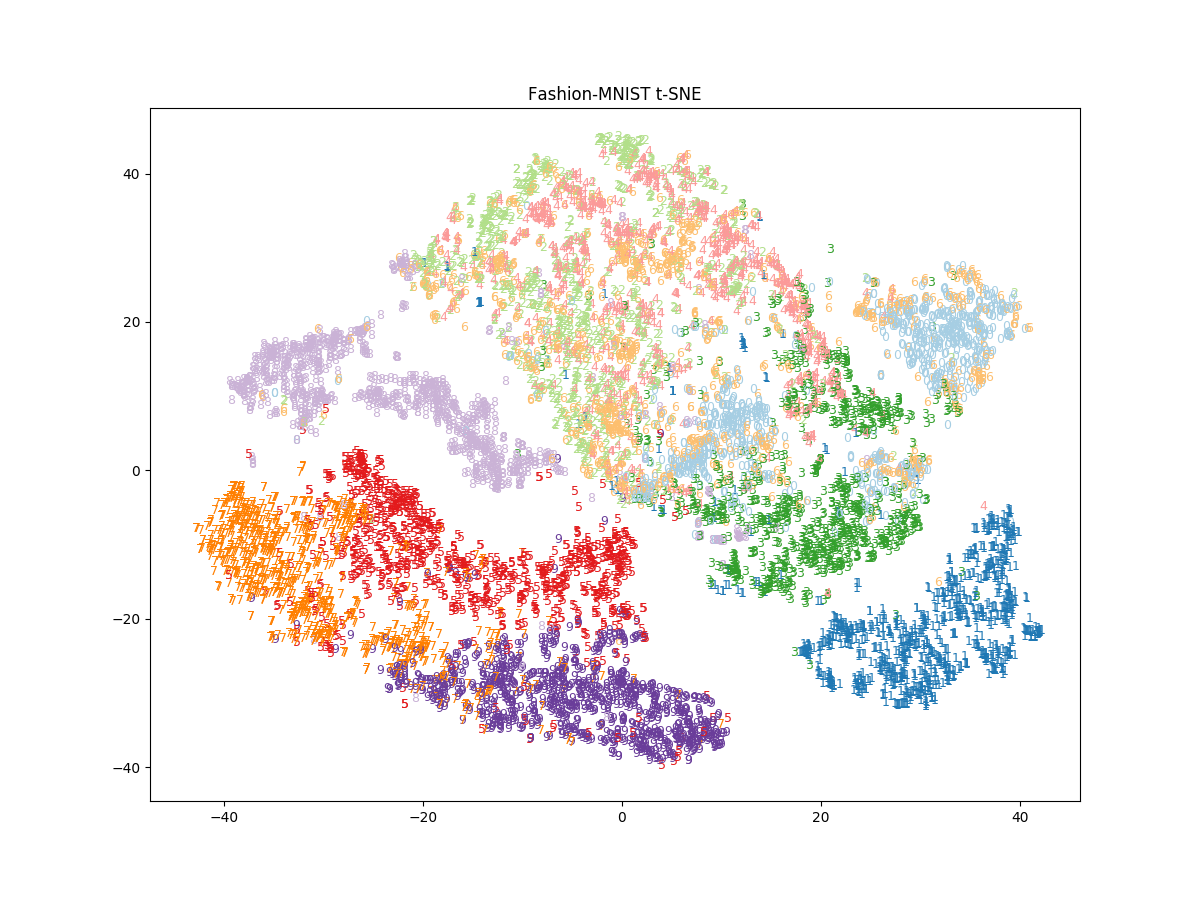
perplexity = 50
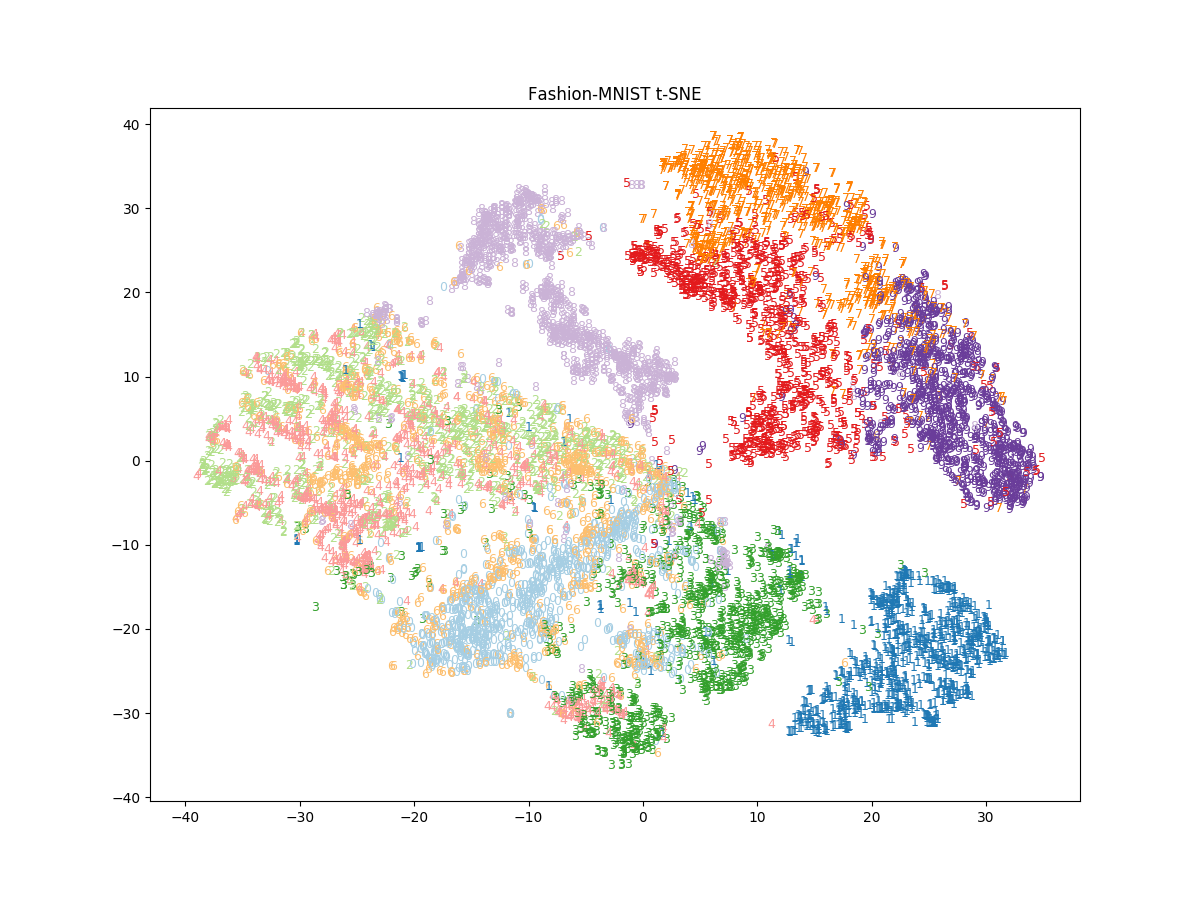
perplexity = 500
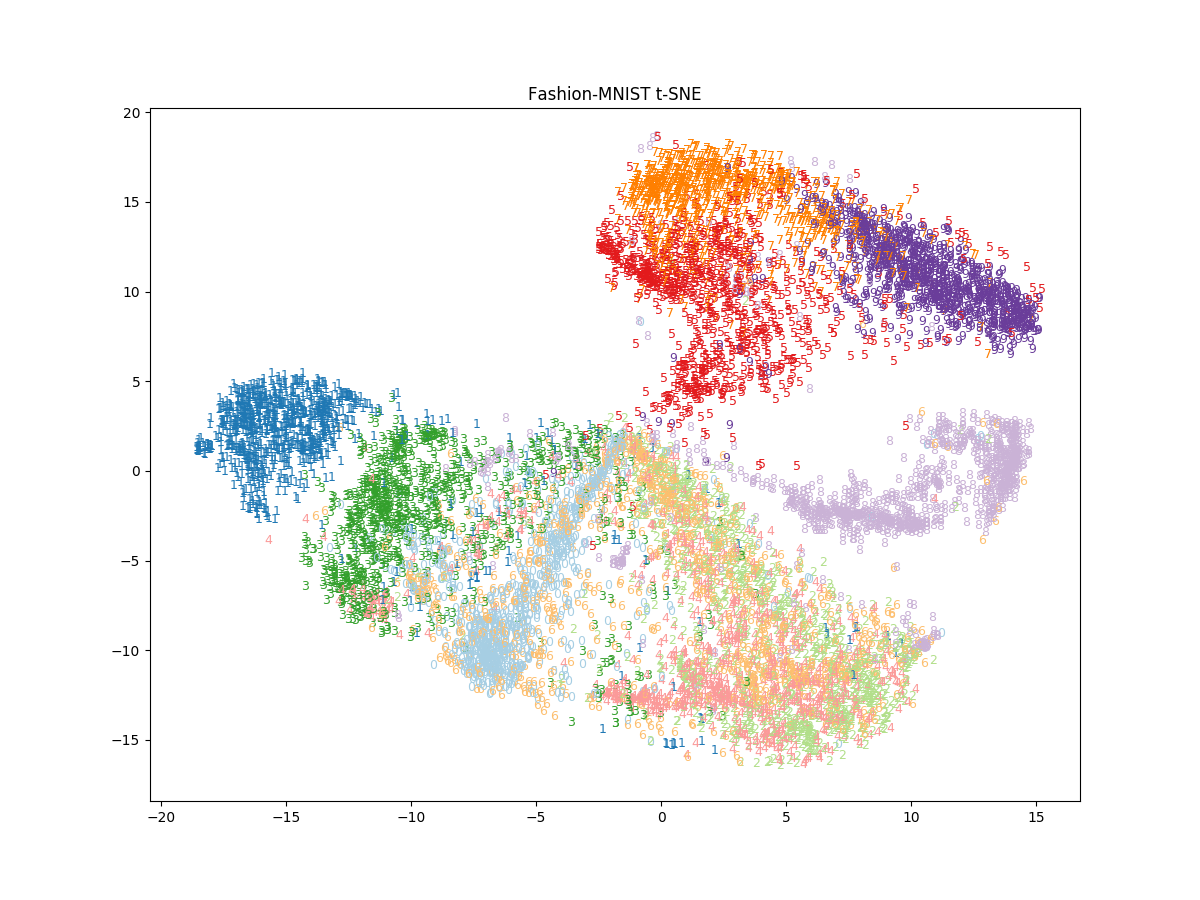
perplexity を大きくすると似ているサンプルはより密集するような結果となった。
また, PCA の結果が以下。
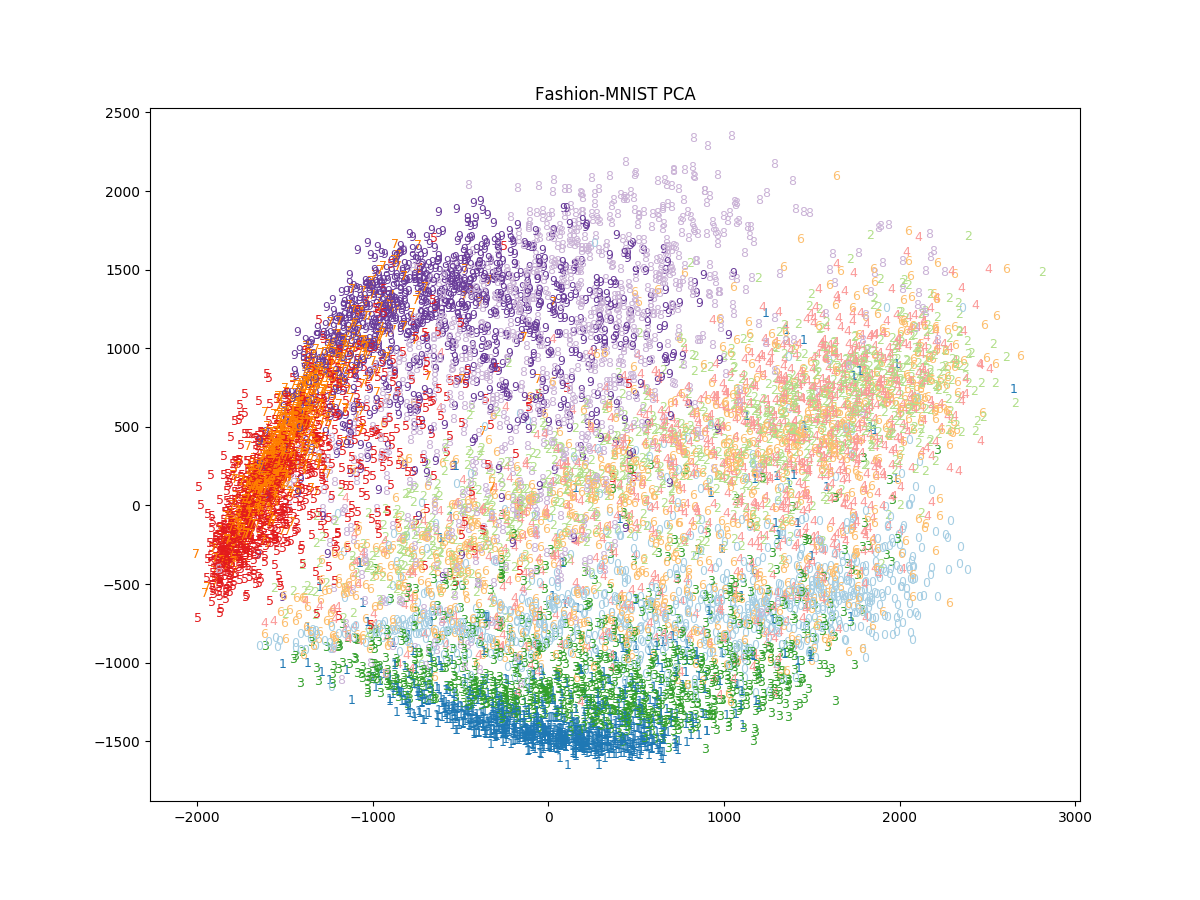
PCA, t-SNE に共通して Sandal, Sneaker, Ankle boot などの履物が近いところにプロットされており直感と合っている。一方, T-shirt/top, Pullover, Coat はどちらも上手くクラスタリングできていない。Bag は PCA では上手く分離できていないが, t-SNE では上手く分離されいる。また, t-SNE では Trouser (ズボン) も他のクラスタから分離されている。
[1] Stochastic Neighbor Embedding [Geoffrey Hinton and Sam Roweis, 2002]
[2] Learning Distributed Representations of Concepts using Linear Relational Embedding [Alberto Paccanaro and Geoffrey Hinton, 2000]
[3] Visualizing Data using t-SNE [Laurens van der Maaten and G.E. Hinton, 2008]
[4] Barnes-Hut-SNE [Laurens van der Maaten, 2013]
[5] Accelerating t-SNE using Tree-Based Algorithms [Laurens van der Maaten, 2014]
[6] Visualizing Data Using t-SNE (slide)
[7] Python crashes when calculating large t-SNE
[8] The Barnes-Hut Approximation