今回はベイジアンネットワークについて調べてみました。
- グラフィカルモデル
- ベイジアンネットワーク
- ベイジアンネットワークの構造学習
- ベイジアンネットワークのパラメータ学習
- R でベイジアンネットワーク
1. グラフィカルモデル
グラフィカルモデルは確率モデルにグラフ構造を与える。グラフィカルモデルには大きく以下の2種類がある。
- ベイジアンネットワーク: 確率的な因果関係をモデル化。有向非巡回グラフで表現。
- マルコフ確率場: 確率的な相互の依存関係をモデル化。無向グラフで表現。
ベイジアンネットワーク (Bayesian Network) は因果関係、データの生成過程、階層ベイズモデルの表現として用いられ, 具体的な応用分野はゲノム解析や消費者行動のモデリング, レコメンデーションなど多岐に渡る。簡単な例として, 血液の遺伝子型と血液型の関係が挙げられる。血液型 X は遺伝子型 Z によって決まり, Z -> X のように方向のある関係として表現される。有向非巡回グラフ (DAG) の有向とは向きがあること, 非巡回であるとはある確率変数が他の確率変数に与えた影響が巡り巡って自分のところに来る影響を考えないことを意味する。
一方, 確率な依存関係というのは方向性があるものだけとは限らない。相互的な依存関係もあり, その場合はマルコフ確率場 (Markov Random Field; MRF) で表現できる。代表的なマルコフ確率場として, イジングモデル (Ising model) と呼ばれる強磁性体の相転移を分析するために導入された数理模型がある。イジングモデルでは格子上の各点がプラスかマイナスを取り, 各点の状態は周りの状態から確率的に決まる。(ギブス分布)
似たような身近な現象としてはラーメン屋の横に並んだカウンター席で, 端に1人だけ座っている時に次の人がすぐ横の席には座りにくいような状況が挙げられる。
DAG から無向グラフを作る操作をモラル化 (moralization) という。
2. ベイジアンネットワーク
ベイジアンネットワークはグラフを用いた変数間の条件付き独立性で表現される。
条件付き独立性とは, 確率変数 X, Y, Z について Z の値が観測されているという条件のもとでは、X と Y が独立であることを指す。
言い換えると、強く関係している X, Y が Z の値で層別することで, その残りの変動が無関係になる。
2.1 有向分離
X, Y, Z があるグラフ G において X と Y をつなぐすべてのパスが Z によって完全にブロック (条件付き独立) されている時, X と Y は Z を所与として 有向分離(D-separation) されているという。
有向分離のごく簡単な例を示す。以下の head-to-tail の DAG において Z が観測 (インスタンス化) されることで X, Y はブロックされる。
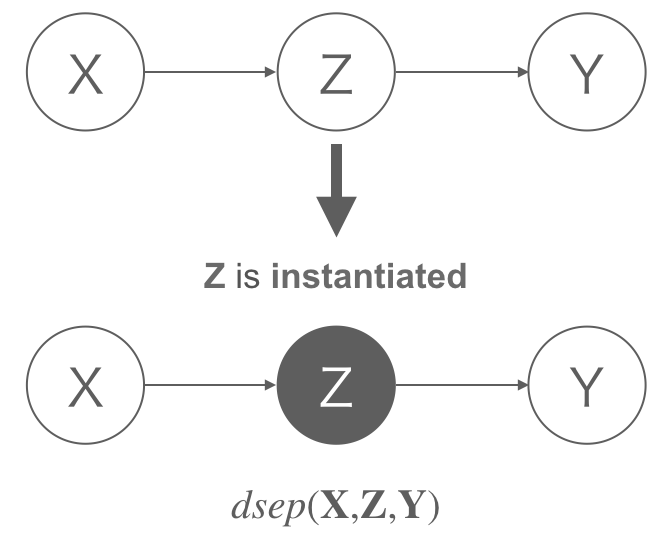
実際のケースではより複雑な DAG で有向分離かを判定する。
2.2 ベイジアンネットワークの定義
参考文献からベイジアンネットワークの定義を引用する。
有限頂点集合 V, 直積集合の部分集合 (辺) E として, 有向非巡回グラフ G = (V, E) が与えられているとする。確率変数の有限集合 X = {X_i} i ∈ V が, 任意の i ∈ V で,

を満たすとき, グラフ構造 G をもつベイジアンネットワークであるという。(pa は親, ndes は非子孫を表す)
2.3 因子分解
ベイジアンネットワークは分離の条件下でグラフィカルモデルに DAG を仮定することで, 同時確率分布を条件付き確率の積で因子分解できる。

これにより組み合わせの数が減り計算量が減少できる。
3. ベイジアンネットワークの構造学習
構造学習 (structure learning) はグラフの形そのものを学習するタスクで, データから確率変数間の矢印を学習する。構造学習はモデル選択の問題で, 学習の難しさは可能なグラフの数 (モデル) が膨大になることである。
ベイジアンネットワークの構造学習には条件付き独立性を用いる方法とスコア関数を最大化する方法がある。
条件付き独立性を用いる方法には以下のアルゴリズムがある。
- SGSアルゴリズム
- PCアルゴリズム
- GSアルゴリズム
スコア関数を最大化する方法には以下がある。
- Chow–Liuのアルゴリズム
- Max-Min Hill-Climbing (MMHC)
4. ベイジアンネットワークのパラメータ学習
パラメータ学習は背後にあるグラフの構造を既知とした時, グラフィカルモデルを因子分解したときに現れる関数のパラメータを学習するタスク。
ベイジアンネットワークの確率は条件付き確率の積となることから, この条件付き確率をデータから求める。
対数尤度関数を最大化する最尤法による学習と, ディリクレ分布を使いMAP推定量やEAP推定量を求めるベイズ法による学習がある。
詳しくは参考文献を参照のこと。
5. R でベイジアンネットワーク
bnlearnパッケージを使い R でベイジアンネットワークを試してみる。
bnlearn は以下の条件付き独立性を用いる構造学習のアルゴリズムをサポートしている。
- PC (the stable version)
- Grow-Shrink (GS)
- Incremental Association Markov Blanket (IAMB)
- Fast Incremental Association (Fast-IAMB)
- Interleaved Incremental Association (Inter-IAMB)
- Max-Min Parents & Children (MMPC)
- Semi-Interleaved Hiton-PC (SI-HITON-PC)
スコア関数を最大化する構造学習のアルゴリズムは以下をサポートしている。
- Hill Climbing (HC)
- Tabu Search (Tabu)
また, 以下のハイブリッドな構造学習のアルゴリズムをサポートしている。
- Max-Min Hill Climbing (MMHC)
- General 2-Phase Restricted Maximization (RSMAX2)
今回は bnlearn に付属する人工 (離散) データセット learning.test を使う。
> library(bnlearn)
>
> data(learning.test)
> df <- learning.test
> tibble::glimpse(df)
Observations: 5,000
Variables: 6
$ A b, b, a, a, a, c, c, b, b, b, b, c, c, c, b, a, a, c, b, b, ...
$ B c, a, a, a, a, c, c, b, b, a, a, c, c, c, c, a, a, c, a, c, ...
$ C b, c, a, a, b, a, b, a, b, b, a, b, b, a, a, b, b, a, b, a, ...
$ D a, a, a, a, c, c, c, b, a, a, b, b, a, c, b, c, a, b, a, b, ...
$ E b, b, a, b, a, c, c, b, c, a, c, c, c, c, c, a, b, b, c, a, ...
$ F b, b, a, b, a, a, a, b, a, a, a, a, b, a, a, a, b, b, a, b, ...
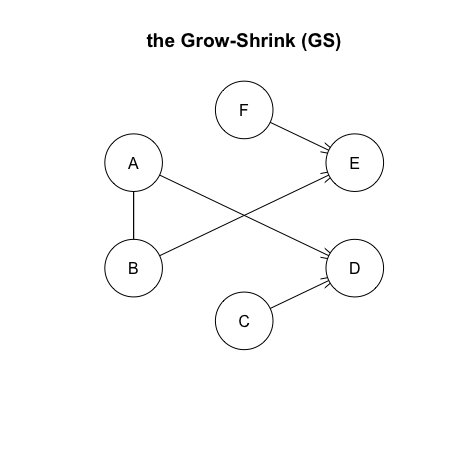
構造学習に条件付き独立性を用いる GS アルゴリズムと IAMB アルゴリズムを試してみる。まずは GS アルゴリズムから。
> # first try the Grow-Shrink algorithm
> res <- gs(df)
> plot(res, main = "the Grow-Shrink (GS)")
続いて, IAMB アルゴリズムを試してみる。
> # now try the Incremental Association algorithm.
> res2 <- iamb(df)
> plot(res2, main = "the Incremental Association")

最後に, 構造学習にスコア関数を用いる Hill-Climbing アルゴリズムを試してみる。 bn.fit() に得られた構造を与えることでパラメータ学習を行う。method に mle を指定すると最尤法, bayes を指定するとベイズ法により学習を行う。
# the hill-climbing (HC)
res3 <- hc(df)
plot(res3, main = "the hill-climbing (HC)")
fitted <- bn.fit(res3, data = df, method = "bayes")

cpdist() や cpquery() により結果から条件付き確率を取得できる。
> particles <- cpdist(fitted,
+ nodes = "A",
+ evidence = (B == "C"))
>
> prop.table(table(particles))
particles
a b c
>
> cpquery(fitted,
+ event = (A == "b"),
+ evidence = (D == "c"))
[1] 0.1068223
Code は GitHub に置いた。
おわりに
参考書籍は『グラフィカルモデル』 (機械学習プロフェッショナルシリーズ) と『確率的グラフィカルモデル』の2冊です。


[1] BayoLink
[2] Bayesian network in R: Introduction
[3] 条件付き独立と有向分離を用いた統計モデルの妥当性チェック
[4] グラフィカルモデルを使いこなす!~有向分離の導入と教師あり学習~
[5] グラフィカルモデルによる確率モデル設計の基本
[6] グラフィカルモデル入門
[7] ベイジアンネット技術とサービス工学におけるビッグデータ活用技術
[8] ベイジアンネットワークを用いたWeb レコメンデーションシステムの開発
[9] ベイジアンネットとレコメンデーション -第5回データマイニング+WEB勉強会@東京