実験計画法
実験の検討対象の要因を因子 (factor), 因子に設定する値を水準 (level) として, 因子の水準組み合わせを 処理 という。
実験により得られるデータは、制御できる因子とその水準による処理効果である主効果や交互作用効果と, 制御できない誤差効果の集積として値がバラつく。
- 主効果: ある因子の結果に対する独立的な効果
- 交互作用: ある因子の結果に対する効果が, 他の因子の水準によって変わるような複数の因子が互いに独立でない場合の効果
どの因子を制御すれば, 結果がどの程度変化するかを知りたいといったケースは工学や生物学など数多くの分野であると思う。
実験計画 (Design of Experiment) はこのバラつきと要因の関係を理解することを主目的とした, 効率のよい実験を設計する方法である。
実験計画に不備があると有用な情報が得られないので, 分散分析など実験後のデータ分析を予め想定し, バラつきを分解できそれぞれを評価できるような実験計画を組む必要がある。
実験には実験誤差が伴う。このバラつきを管理するための基本的な考えとして, フィッシャー (R.A. Fisher) の三原則がある。
- 反復 (replication): 観測時の誤差の影響を除くために同条件で反復する。誤差の評価, 推定。
- 無作為化 (randomization): 系統誤差を偶然誤差に転化する。制御できない可能性のある要因の影響を除き, 偏りを小さくするために条件を無作為化する。
- 局在管理 (local control): 大きな系統誤差の除去。調べたい要因以外は条件を一定にする。
反復回数は統計的検定を踏まえて設定する。臨床試験などではサンプルサイズを検出力 (Power)を考慮した上で設定した方が良さそう。
ラテン方格
3つの因子に対して, 3水準を設定すると 3^3 = 27通り の実験が必要となる。これを完全実施 (full factorial)と言う。
因子が多い場合, 全ての交互作用を考慮すると実験回数は膨大な数となる。
ここで, 事前に交互作用がないとわかっているとすると, 各因子が互いに直交するベクトルとなる ラテン方格 (Latin square) によって 9通り となる。
ラテン方格は下記のように各行や各列にも1回だけ現れる行列。
In [1]: import numpy as np
In [2]: np.array([[1, 2, 3], [2, 3, 1], [3, 1, 2]])
Out[2]:
array([[1, 2, 3],
[2, 3, 1],
[3, 1, 2]])
直交計画
直交計画も, ラテン方格のように実験回数を減らして効率的に実験を設計する方法。
因子の数を4個として, 各水準を3とすると, 4^3 = 64回となるが, このような場合に直交計画は現実的に実施可能な範囲 (最低限の直交性を維持したまま) に保ちながら, できるだけ多くの因子を取りあげて効率的に情報を取り出す方法である。
3因子以上の交互作用は経験的に小さい場合が多いので, この部分に関する実験は省いてしまいたいというのが直感的かもしれない。
直交配列 (orthogonal arrays) はどの2列をとっても, その水準のすべての組み合わせが同数回現れる配列のこと。因子と水準によって, 選択する直交表のサイズは変わる。
Rでは {DoE.base} で直交表を生成できる。上記例だと, L9-3-4の直交表となる。
> require(DoE.base)
> table <- oa.design(nfactors = 4, nlevels = 3)
> table
A B C D
1 1 3 2 3
2 1 1 1 1
3 3 3 3 1
4 2 3 1 2
5 1 2 3 2
6 3 2 1 3
7 2 2 2 1
8 3 1 2 2
9 2 1 3 3
class=design, type= oa
分散分析
直交表に基づき実験を行い得られたデータに対して, 処理の効果の違いが誤差の違いによってどれくらい大きいかを情報 (分散比) を得るために分散分析を行う。
- 全平方和: データ全体のバラつき
- 処理平方和: 各因子に起因する変動
- 残差平方和: 処理では説明できない誤差に起因する変動
全平方和 = 処理平方和 + 残差平方和 で, 基本的に線形モデルである。
下記のような因子の数が4, 各水準が3, 反復回数が2の直交計画を立てたとする。
> table2 <- oa.design(nfactors = 4, nlevels = 3, replication = 2, seed = 1)
> table2
run.no run.no.std.rp A B C D
1 1 3.1 1 3 2 3
2 2 9.1 3 3 3 1
3 3 5.1 2 2 2 1
4 4 6.1 2 3 1 2
5 5 2.1 1 2 3 2
6 6 4.1 2 1 3 3
7 7 8.1 3 2 1 3
8 8 7.1 3 1 2 2
9 9 1.1 1 1 1 1
10 10 1.2 1 1 1 1
11 11 2.2 1 2 3 2
12 12 8.2 3 2 1 3
13 13 5.2 2 2 2 1
14 14 7.2 3 1 2 2
15 15 4.2 2 1 3 3
16 16 6.2 2 3 1 2
17 17 3.2 1 3 2 3
18 18 9.2 3 3 3 1
class=design, type= oa
NOTE: columns run.no and run.no.std.rp are annotation, not part of the data frame
直交表に基づき実験を実施し, 下記のようなデータが得られたとする。
data <- cbind(table, R = c(12, 5, 11, 6, 8, 2, 7, 2, 5, 9, 13, 5, 7, 9, 5, 4, 3, 5))
グラフで, 各因子の水準の効果を確認する。
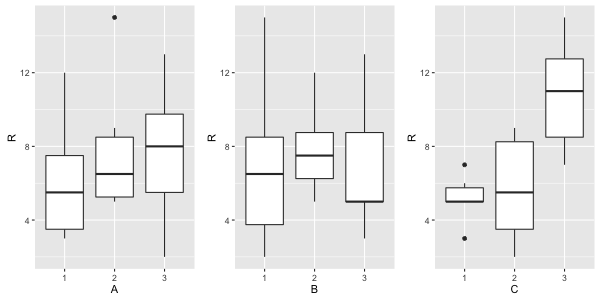
分散分析を行う。stats::aov()は Type-I で逐次平方和が求まる。
res.aov <- aov(R ~ A + B + C + D, data)
summary(res.aov)
# Df Sum Sq Mean Sq F value Pr(>F)
# A 2 10.11 5.06 0.555 0.593
# B 2 3.44 1.72 0.189 0.831
# C 2 118.11 59.06 6.482 0.018 *
# D 2 3.44 1.72 0.189 0.831
# Residuals 9 82.00 9.11
# ---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
分散分析表の見方は下記のような感じ。
- Df: 自由度
- Sum Sq: 平方和 (SS)
- Mean Sq: 平均平方 (SS / Df), 母分散の不偏推定値
- F Value: 分散比
- Pr(>F): p値
因子Cについて p値 が 0.018 で, 5%有意水準とした場合には因子Cの3水準の平均値には有意な差があると言える。
調整平方和 (adjusted SS) を求めたい場合は car::Anova で Type = 2 を指定する。
3 を指定すると二次以上の項の影響も除いて計算した調整平方和が求まる。主効果の影響の検討において交互作用を考慮したい時には 3 の方が良さそう。
model2 <- lm(R ~ A * B * C * D, data = data)
res.car.anova <- car::Anova(model2, Type = 2)
print(res.car.anova)
# Anova Table (Type II tests)
#
# Response: R
# Sum Sq Df F value Pr(>F)
# A 10.111 2 0.5549 0.59260
# B 3.444 2 0.1890 0.83097
# C 118.111 2 6.4817 0.01805 *
# D 3.444 2 0.1890 0.83097
# A:B 0
# A:C 0
# B:C 0
# A:D 0
# B:D 0
# C:D 0
# A:B:C 0
# A:B:D 0
# A:C:D 0
# B:C:D 0
# A:B:C:D 0
# Residuals 82.000 9
# ---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
今回のようなバランスデータ (balanced data) [1]では, 逐次平方和 (Type-I) と調子平方和 (Type-II) で結果は一致している。
Code は GitHub に置いた。
コンジョイント分析
直交表のマーケティング分野への応用例として, コンジョイント分析 (Luce & Tukey, 1964) がある。
実験計画法では分散の管理が目的の一つであったが, コンジョイント分析では製品またはサービスを構成する要素 (属性) を消費者がどの程度重視しているかを分析する。
属性の水準の組み合わせをサービスコンセプトとして, 回答者に選考順位 (ランキングや評定尺度法, 一対比較法)を決めてもらう。この組み合わせを減らすために, 直交表を用いる。
得られたデータから下記を計算する。
- 効用値: その水準がどの程度好まれるか, どれくらい魅力を感じられるか。各属性で効用値の平均が0になるように調整する。
- 重要度: 商品選択に各属性がどの程度影響を及ぼすか。各属性内の効用値の分散で計算される。
- 総合効用値: コンセプトの全体的魅力度を表す。そのコンセプトを決める水準の効用値を合計する。
Rでは, 計画段階で {DoE.base}, {AlgDesign}, {conjoint} による直交表の生成, 分析段階では lm, glm や MASS::plor() による順序ロジット分析, または survival::clogit() による条件付きロジット分析などがある。
コンジョイント分析については, 購買心理を読み解く統計学―実例で見る心理・調査データ解析28を参考にしました。

[1] どの因子 (列) でも各水準のデータが同数になっているデータセット
[2] Rで実験計画法 後編
[3] Rでコンジョイント分析
[4] Rによる分散分析でタイプIII平方和を使う時の落とし穴
[5] データ解析環境Rによる選択型コンジョイント分析入門