この記事は Python Advent Calendar 2015 19日目の記事です。
MC法 (Monte Carlo Method) からスタートして, MCMC (Markov Chain Monte Carlo) を Python で書いてみます。
MC法による円周率の近似計算
MC法 (Monte Carlo Method)は乱数を利用した計算アルゴリズム。
MC法の hello world 的な例題として, 円周率の近似値を計算する。
import numpy as np
import matplotlib.pyplot as plt
def main():
N = 100000
x = np.random.uniform(-1.0, 1.0, N)
y = np.random.uniform(-1.0, 1.0, N)
inside_circle = []
for i in xrange(N):
if (x[i]**2 + y[i]**2) < 1.0:
inside_circle.append(True)
else:
inside_circle.append(False)
print(2.0**2 * float(inside_circle.count(True)) / float(N)) # => 3.13632
plt.scatter(x, y, c=inside_circle, s=5, edgecolor='None')
plt.xlim(-1.0, 1.0)
plt.ylim(-1.0, 1.0)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
if __name__ == '__main__':
main()
正方形の領域に一様分布から 10万点を取り出し打ち出す。
円の中に入った点の個数をカウントすると正方形の面積と円の面積の比が求まるので, これに正方形の面積を掛けると, 円の面積(=円周率)の近似値が出てくる。

結果は 3.13632 と求まり, 半径が 1 なので円周率の近似値となる。点の個数と精度の関係は Chernoffの不等式 で見積もることができる。
同様に球の体積でも MC法で 4.19312 と近似値計算は上手くいっている。
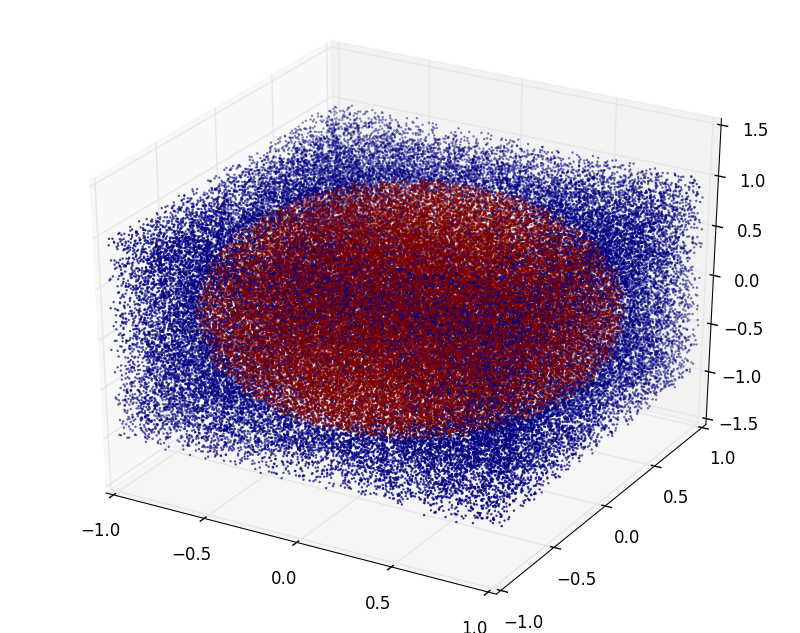
MC法による超球の体積近似計算
円や球ではMC法でそれなりの精度で近似値が得られた。
同様の方法で, 次元を上げていった時の n次元超球の体積が上手く求まるか試してみる。
半径 r の n次元超球の体積は下記で求まる。

超球の体積をMC法で 1次元から24次元まで求め, 理論値と比較してみる。
import math
import numpy as np
import matplotlib.pyplot as plt
def V(n):
return math.pi**(n/2.0) / math.gamma(n/2.0+1.0)
def count_point(N, n):
x = []
count = 0
for i in range(n):
x.append(np.random.uniform(-1.0, 1.0, N))
for i in range(N):
r = 0.0
for j in range(n):
r += x[j][i]**2.0
if r < 1.0:
count += 1
return count
def main():
tv = []
mc = []
N = 100000
for n in range(1, 25):
c = count_point(N, n)
tv.append(V(n))
mc.append(2.0**n * float(c) / float(N))
print(n, ': Dim')
print('Theoretical Value:', V(n))
print('Monte Carlo :', 2.0**n * float(c) / float(N))
x = np.arange(1, 25, 1)
plt.plot(x, tv)
plt.plot(x, mc)
plt.xlabel('dim')
plt.ylabel('V(r=1)')
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
下記が結果で, MC法では 15次元で体積が求まらなくなってしまった。
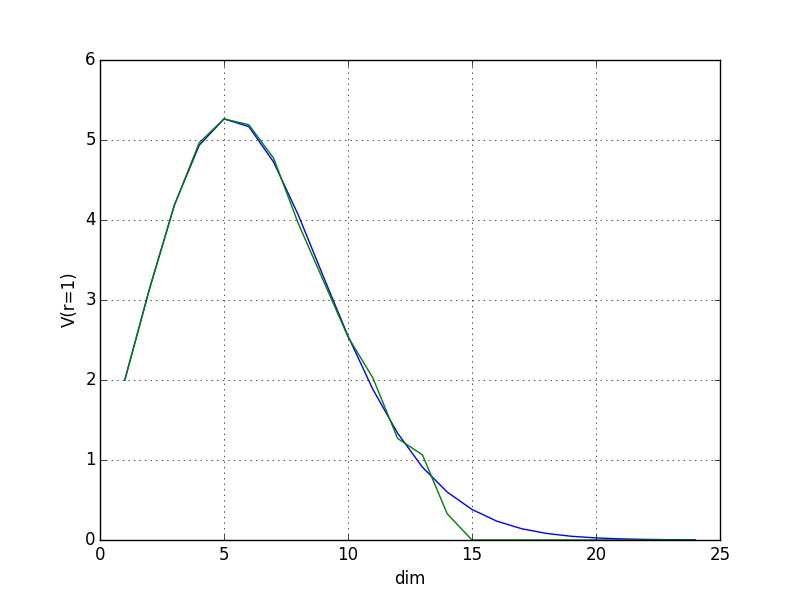
このように, 高次元になるほど単純な MC法では超球の内部へ稀にしか入らず, 近似計算が上手くいかなくなる。(次元の呪い)
MCMC
MCMC (Markov Chain Monte Carlo, マルコフ連鎖モンテカルロ法) はMC法の中でも, 調べたい分布を不変分布 [3]とするマルコフ連鎖 [4]をシミュレートし, サンプルを生成する方法である。生成したサンプルの分布を調べることで, パラメータ推定に使うこともできる。
確率密度の大きいところを探しながらサンプルを生成できる点が特徴で, 単純な MC法によるn次元超球の体積計算のように無駄なサンプルが増えてしまう影響を抑制できる。
MCMCに関する性質・条件 (既約性, エルゴード性, 詳細釣り合い条件) 等については専門書を参考に。
メトロポリス・ヘイスティングス法
メトロポリス・ヘイスティングス法 (Metropolis-Hastings algorithm, M-H法) は ギブス・サンプラー (Gibbs sampling, Gibbs sampler)と メトロポリス法 (Metropolis method)を含む MCMCの代表的な手法のひとつ。
ギブス・サンプラー
ギブス・サンプラーは新しいサンプルを全て受容できる効率的なサンプリング手法。
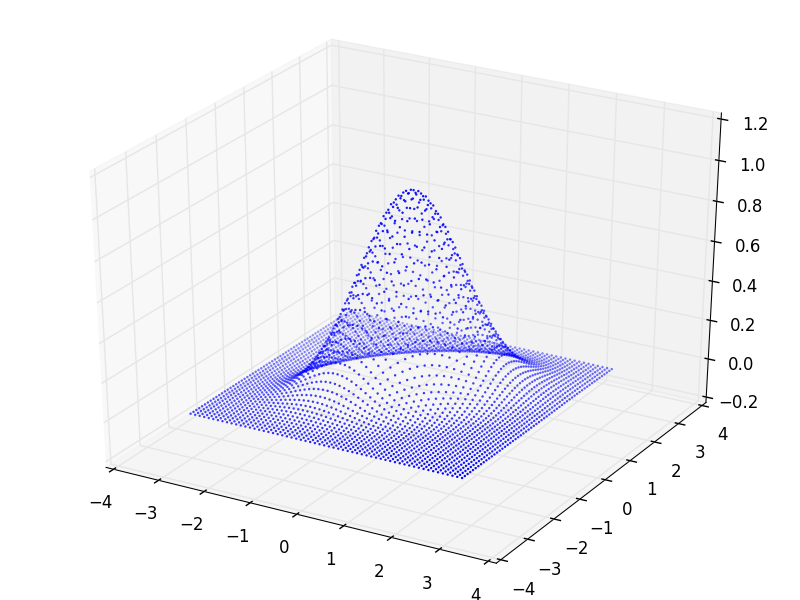
例として二変量正規分布で試してみる。(数式引用 [2])

二変量正規分布を3Dプロットしてみる。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D
def range_ex(start, end, step):
while start + step < end:
yield start
start += step
# P(x) : Target distribution
def P(x1, x2, b):
return np.exp(-1/2 * (x1**2 - 2*b*x1*x2 + x2**2))
def main():
xs = []
ys = []
zs = []
b = 0.5
for i in range_ex(-3, 3, 0.1):
for j in range_ex(-3, 3, 0.1):
xs.append(i)
ys.append(j)
zs.append(P(i, j, b))
ax = Axes3D(plt.figure())
ax.scatter3D(xs, ys, zs, s=3, edgecolor='None')
plt.show()
上記の二変量正規分布の x_1, x_2について, 一方を固定した場合の条件付き確率がわかっているとすると, ギブス・サンプラーは小さい N の大きさで効率的にサンプルを得られる。一方を固定しているので, 平面上をカクカク動くのが特徴。
def gibbs(N, thin):
s = []
x1 = 0.0
x2 = 0.0
for i in xrange(N):
for j in xrange(thin):
x1 = np.random.normal(b * x2, 1) # P(x1|x2)
x2 = np.random.normal(b * x1, 1) # P(x2|x1)
s.append((x1,x2))
return np.array(s)
def main():
N = 3000
thin = 500
burn_in = 0.2
sample = gibbs(N, thin)
plt.scatter(
sample[int(N * burn_in):,0],
sample[int(N * burn_in):,1],
s=3,
edgecolor='None'
)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
print('x1:', np.mean(sample[int(N * burn_in):,0]), np.var(sample[int(N * burn_in):,0]))
# => x1: 0.00741907569473 1.32326519155
print('x2:', np.mean(sample[int(N * burn_in):,1]), np.var(sample[int(N * burn_in):,1]))
# => x2: -0.00980409857562 1.33662629729
if __name__ == '__main__':
main()
初期状態の影響が残っている最初の方の列を捨てると, 残りの列は定常分布, つまり解析したい分布からのサンプル列と考えられる。今回は, burn_in = 0.2 として最初の 20%は捨てている。

メトロポリス法
ギブス・サンプラーでは条件付確率を用いたが, 条件付確率を求めるのが容易でない場合は, メトロポリス法を用いる。
条件付確率の代わりに目標分布 p(z)を近似する簡単な提案分布 q(z) を用いる。ただし, q(z)から得られた 新しいサンプルの候補について, 受容か棄却かを決定するのは p(z)を使って求める。
遷移する確率は a が 1 より大きいと必ず遷移し, 1以下の場合はその確率 ([0,1] の一様分布からの乱数と比較した結果)で遷移する。
import copy
import numpy as np
import matplotlib.pyplot as plt
# P(x) : Target distribution
def P(x1, x2, b):
return np.exp(-0.5 * (x1**2 - 2*b*x1*x2 + x2**2))
# Q(x) : Proposal distribution
def Q(c, mu1, mu2, sigma):
return (c[0] + np.random.normal(mu1, sigma), c[1] + np.random.normal(mu2, sigma))
def metropolis(N, mu1, mu2, sigma, b):
current = (10, 10)
sample = []
sample.append(current)
accept_ratio = []
for i in xrange(N):
candidate = Q(current, mu1, mu2, sigma)
T_prev = P(current[0], current[1], b)
T_next = P(candidate[0], candidate[1], b)
a = T_next / T_prev
if a > 1 or a > np.random.uniform(0, 1):
# Update state
current = copy.copy(candidate)
sample.append(current)
accept_ratio.append(i)
print('Accept ratio:', float(len(accept_ratio)) / N)
return np.array(sample)
def main():
b = 0.5
mu1 = 0
mu2 = 0
sigma = 1
N = 30000
burn_in = 0.2
sample = metropolis(N, mu1, mu2, sigma, b)
plt.scatter(
sample[int(len(sample) * burn_in):, 0],
sample[int(len(sample) * burn_in):, 1],
alpha=0.3,
s=5,
edgecolor='None'
)
plt.title('MCMC (Metropolis)')
plt.show()
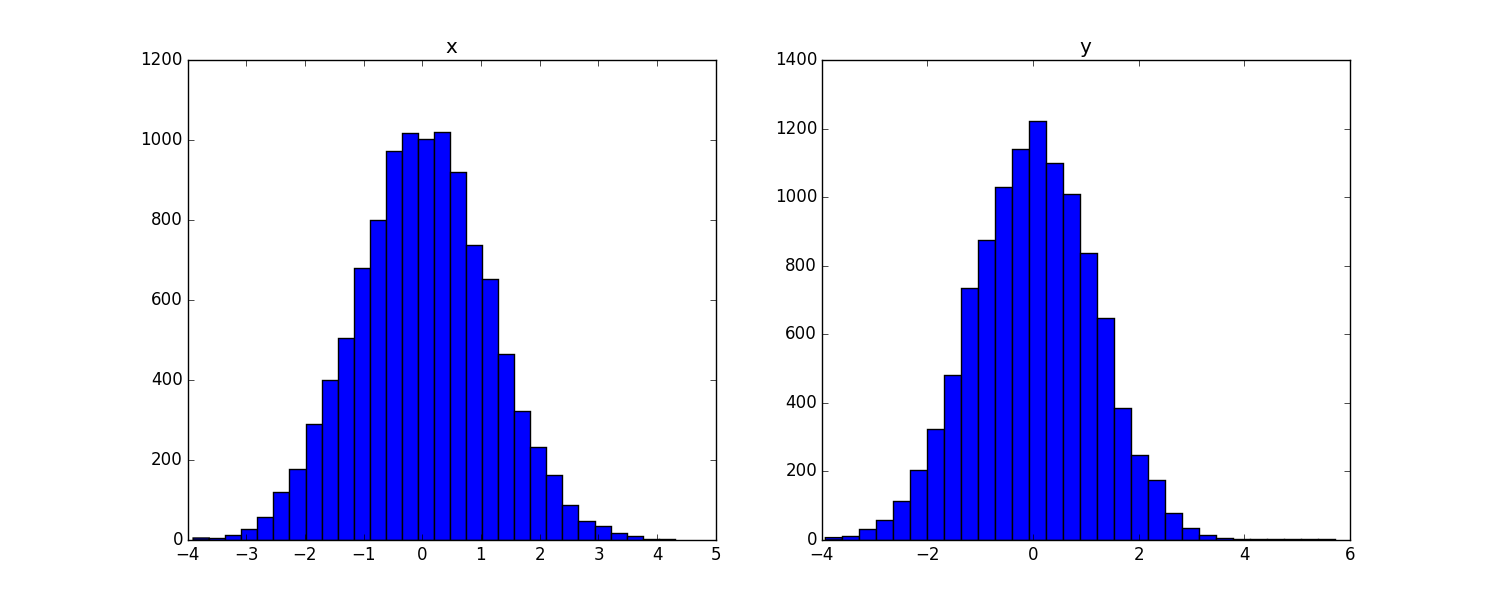
fig = plt.figure(figsize=(15, 6))
ax = fig.add_subplot(121)
plt.hist(sample[int(N * burn_in):,0], bins=30)
plt.title('x')
ax = fig.add_subplot(122)
plt.hist(sample[int(N * burn_in):,1], bins=30)
plt.title('y')
plt.show()
print('x:', np.mean(sample[int(len(sample) * burn_in):,0]), np.var(sample[int(len(sample) * burn_in):,0]))
# => x: -0.00252259614386 1.26378688755
print('y:', np.mean(sample[int(len(sample) * burn_in):,1]), np.var(sample[int(len(sample) * burn_in):,1]))
# => y: -0.0174372516771 1.24832585103
if __name__ == '__main__':
main()
新しいサンプルの候補が, 受容された比率は, 0.5623 となった。
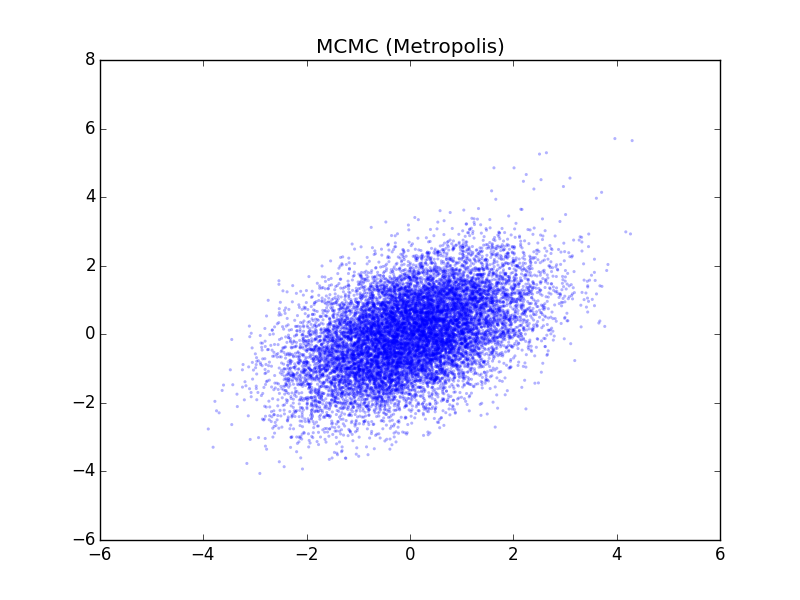
MCMCで生成した多数のサンプルの分布から, 平均・分散といった要約統計量やEAP推定量, ベイズ信頼区間といった欲しい情報を求めることができる。
Codeは Githubに置いた。
おわりに
間違いを見つけられましたら, ご指摘いただけると嬉しいです。 様々な MCMC を可視化している The Markov-chain Monte Carlo Interactive Gallery は勉強になります。 最後に参考書籍を何冊か載せておきます。
『東京大学工学教程 情報工学 機械学習』はMCMC以外にも, オンライン学習や正則化の辺りが分かり易かったです。 (書籍の基となった資料はこちら)

MCMC (動的モンテカルロ法)は元々, 統計物理と関連が深いことを『ベイズ統計と統計物理』を読んで知りました。

『基礎からのベイズ統計学』はベイズ統計の歴史的背景や, Stanでも実装されているハミルトニアン・モンテカルロ法 (HMC) の話が分かり易かったです。

[1] Gibbs sampler in various languages (revisited)
[2] 第11章 サンプリング法
[3] 不変分布とは, (ベイズ統計的な意味で) ある一定の確率分布へと収束すること。
[4] t の状態が t-1 からのみの条件付確率で決定することをマルコフ性と言い, その確率過程をマルコフ過程と言う。その中でも離散的な状態または時間の場合がマルコフ連鎖。
[5] 例えば, 正規分布の場合, MCMCで得られた統計量から確率密度を確認したければ R で `curve(dnorm(x, mu, sigma)))` でできる (あまり意味はないけど…)
[6] マルコフ連鎖モンテカルロ法の最近の展開 (2001)
[7] 2 次元正規分布 – 龍谷大学