Apache Drillを使ってみました。Apache Drillは JSON, CSV, TSVのようなファイルや, Hive, HBase, MongoDBのようなデータソースに対して接続して, SQLクエリを投げることができます。1.0時点ではLTSVはサポートしていないようです。
1.2から ANSI SQLのサポートを開始するようです。
試したことは下記3点です。
- MovieLens (CSV) の集計
- NginxのLog (LTSV => JSON) 集計
- DrillからMongoDBにアクセス
Apache Drillのインストール
OSXだとbrewでインストールできる。
$ brew install apache-drill
drill-in-10-minutesを試してみる。まずは起動。
$ cd /usr/local/Cellar/apache-drill/1.0.0
$ bin/drill-embedded
employee.jsonに対して SELECT を投げてみる。
0: jdbc:drill:zk=local> SELECT * FROM cp.`employee.json` LIMIT 3;
+--------------+------------------+-------------+------------+--------------+---------------------+-----------+----------------+-------------+------------------------+----------+----------------+------------------+-----------------+---------+--------------------+
| employee_id | full_name | first_name | last_name | position_id | position_title | store_id | department_id | birth_date | hire_date | salary | supervisor_id | education_level | marital_status | gender | management_role |
+--------------+------------------+-------------+------------+--------------+---------------------+-----------+----------------+-------------+------------------------+----------+----------------+------------------+-----------------+---------+--------------------+
| 1 | Sheri Nowmer | Sheri | Nowmer | 1 | President | 0 | 1 | 1961-08-26 | 1994-12-01 00:00:00.0 | 80000.0 | 0 | Graduate Degree | S | F | Senior Management |
| 2 | Derrick Whelply | Derrick | Whelply | 2 | VP Country Manager | 0 | 1 | 1915-07-03 | 1994-12-01 00:00:00.0 | 40000.0 | 1 | Graduate Degree | M | M | Senior Management |
| 4 | Michael Spence | Michael | Spence | 2 | VP Country Manager | 0 | 1 | 1969-06-20 | 1998-01-01 00:00:00.0 | 40000.0 | 1 | Graduate Degree | S | M | Senior Management |
+--------------+------------------+-------------+------------+--------------+---------------------+-----------+----------------+-------------+------------------------+----------+----------------+------------------+-----------------+---------+--------------------+
3 rows selected (0.198 seconds)
!quit で Drillを Stopできる。
MovieLensの集計
非商用の推薦システムを運営するMovieLensが公開しているデータセット。grouplensからダウンロードできる。
23万ユーザによる計3万本の映画に対する評価を含んでいる。
“Full: 21,000,000 ratings and 510,000 tag applications applied to 30,000 movies by 230,000 users. Last updated 8/2015.”
データがCSVなので text-files-csv-tsv-psvを参考にした。
headerを含んでいるcsvは, Drillでheaderを無視する方法がわからなかったので悔しいがcsvをいじって削除した。
(コメントでご指摘を頂いてるように Storage Plugins の設定で skipFirstLine を true にセットすることで skipすることができます。drill-embeddedであれば, Drill UI が利用できhttps://localhost:8047/storage/dfs からブラウザ上で設定可能です。2015/09/23 追記)
$ vim ratings.csv
$ head ratings-noheader.csv
1,50,4.0,1329753504
1,296,4.0,1329753602
1,318,4.5,1329753494
1,527,4.5,1329753507
1,541,3.0,1329753607
1,608,4.0,1329753638
1,750,3.0,1329753525
1,858,4.5,1329753498
1,1197,4.5,1329753573
1,1213,4.5,1329753565
平均評価の高い映画の上位30件を表示してみる。
0: jdbc:drill:zk=local> SELECT movies.columns[0] AS movieID, movies.columns[1] AS title, AVG(cast(ratings.columns[2] as DOUBLE)) AS avg_rating FROM dfs.`/path/to/your/MovieLens/ml-latest/movies-noheader.csv` AS movies JOIN dfs.`/path/to/your/MovieLens/ml-latest/ratings-noheader.csv` AS ratings ON ratings.columns[1] = movies.columns[0] GROUP BY movies.columns[0], movies.columns[1], ratings.columns[2] ORDER BY avg_rating desc LIMIT 30;
+----------+---------------------------------------------------------------------+-------------+
| movieID | title | avg_rating |
+----------+---------------------------------------------------------------------+-------------+
| 34 | Babe (1995) | 5.0 |
| 904 | Rear Window (1954) | 5.0 |
| 1625 | Game, The (1997) | 5.0 |
| 14 | Nixon (1995) | 5.0 |
| 257 | Just Cause (1995) | 5.0 |
| 412 | Age of Innocence, The (1993) | 5.0 |
| 296 | Pulp Fiction (1994) | 5.0 |
| 1061 | Sleepers (1996) | 5.0 |
| 2329 | American History X (1998) | 5.0 |
| 10 | GoldenEye (1995) | 5.0 |
| 76 | Screamers (1995) | 5.0 |
| 193 | Showgirls (1995) | 5.0 |
| 380 | True Lies (1994) | 5.0 |
| 318 | Shawshank Redemption, The (1994) | 5.0 |
| 1246 | Dead Poets Society (1989) | 5.0 |
| 32 | Twelve Monkeys (a.k.a. 12 Monkeys) (1995) | 5.0 |
| 6380 | Capturing the Friedmans (2003) | 5.0 |
| 3897 | Almost Famous (2000) | 5.0 |
| 2762 | Sixth Sense, The (1999) | 5.0 |
| 2023 | Godfather: Part III, The (1990) | 5.0 |
| 2692 | Run Lola Run (Lola rennt) (1998) | 5.0 |
| 3948 | Meet the Parents (2000) | 5.0 |
| 4783 | Endurance: Shackleton s Legendary Antarctic Expedition, The (2000) | 5.0 |
| 43 | Restoration (1995) | 5.0 |
| 185 | Net, The (1995) | 5.0 |
| 63082 | Slumdog Millionaire (2008) | 5.0 |
| 4979 | Royal Tenenbaums, The (2001) | 5.0 |
| 261 | Little Women (1994) | 5.0 |
| 590 | Dances with Wolves (1990) | 5.0 |
| 953 | It s a Wonderful Life (1946) | 5.0 |
+----------+---------------------------------------------------------------------+-------------+
30 rows selected (67.584 seconds)
NginxのLog集計
Nginxで動いているBlogのlogを分析してみる。まず, /etc/nginx/nginx.conf の log_formatを LTSV (Labeled Tab-separated Values)に変更して, 6時間放置してみる。
http {
...
log_format ltsv 'domain:$host\t'
'host:$remote_addr\t'
'user:$remote_user\t'
'time:$time_local\t'
'method:$request_method\t'
'path:$request_uri\t'
'protocol:$server_protocol\t'
'status:$status\t'
'size:$body_bytes_sent\t'
'referer:$http_referer\t'
'agent:$http_user_agent\t'
'response_time:$request_time\t'
'cookie:$http_cookie\t'
'set_cookie:$sent_http_set_cookie\t'
'upstream_addr:$upstream_addr\t'
'upstream_cache_status:$upstream_cache_status\t'
'upstream_response_time:$upstream_response_time';
access_log /var/log/nginx/access.log ltsv;
...
}
LTSV formatの logが得られた。
domain:www.fisproject.net host:xx.xxx.xx.xx user:- time:19/Sep/2015:20:49:32 +0900 method:GET path:/tag/memcached/ protocol:HTTP/1.1 status:200 size:27517 referer:- agent:Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html) response_time:0.362 cookie:- set_cookie:- upstream_addr:127.0.0.1:xxxx upstream_cache_status:- upstream_response_time:0.362
...
ltsviewを使って, LTSVをJSONに変換する。
$ cat access.log | ltsview -j --no-colors > access.json
変換後は以下のスキーマになる。
{
"domain": "www.fisproject.net",
"host": "xx.xxx.xx.xxx",
"user": "-",
"time": "19/Sep/2015:20:49:32 +0900",
"method": "GET",
"path": "/tag/memcached/",
"protocol": "HTTP/1.1",
"status": "200",
"size": "27517",
"referer": "-",
"agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)",
"response_time": "0.362",
"cookie": "-",
"set_cookie": "-",
"upstream_addr": "127.0.0.1:xxxx",
"upstream_cache_status": "-",
"upstream_response_time": "0.362"
}
...
DrillでJSONを扱うにはjson-data-modelを参考にする。
HTTPStatusCode別の件数。
0: jdbc:drill:zk=local> SELECT cast(status as INT) AS status_code, count(*) FROM dfs.`/path/to/your/access.json` GROUP BY cast(status as INT);
+--------------+---------+
| status_code | EXPR$1 |
+--------------+---------+
| 304 | 648 |
| 200 | 1782 |
| 404 | 37 |
| 499 | 24 |
| 302 | 26 |
| 301 | 32 |
| 400 | 2 |
| 206 | 2 |
| 500 | 2 |
+--------------+---------+
HTTPメソッド別の件数。
0: jdbc:drill:zk=local> SELECT `method`, count(*) FROM dfs.`/path/to/your/access.json` GROUP BY `method`;
+---------+---------+
| method | EXPR$1 |
+---------+---------+
| GET | 2284 |
| POST | 268 |
| - | 2 |
| HEAD | 1 |
+---------+---------+
最大応答時間の上位10件。
0: jdbc:drill:zk=local> SELECT path, MAX(cast(response_time as DOUBLE)) AS max_response_time FROM dfs.`/path/to/your/access.json` GROUP BY path ORDER BY max_response_time desc LIMIT 10;
+------------------------------+--------------------+
| path | max_response_time |
+------------------------------+--------------------+
| /feed/ | 12.532 |
| / | 5.224 |
| /2015/04/tika/ | 5.198 |
| /api/v1/stock_info | 5.115 |
| /api/v1/asset | 4.796 |
| /category/admin-diary/feed/ | 4.5 |
| /favicon.ico | 4.247 |
| /api/v1/incentives | 4.19 |
| /xmlrpc.php | 3.171 |
| /tag/linux/feed/ | 2.956 |
+------------------------------+--------------------+
平均応答時間の上位10件。
0: jdbc:drill:zk=local> SELECT path, AVG(cast(response_time as DOUBLE)) FROM dfs.`/path/to/your/access.json` GROUP BY path ORDER BY AVG(cast(response_time as DOUBLE)) desc LIMIT 10;
+-----------------------------------------------------------+--------------------+
| path | EXPR$1 |
+-----------------------------------------------------------+--------------------+
| /api/v1/xxxxxxxxxx | 5.115 |
| /api/v1/xxxxx | 4.796 |
| /category/admin-diary/feed/ | 4.5 |
| /api/v1/incentives | 4.19 |
| /feed/ | 3.371483870967742 |
| /tag/linux/feed/ | 2.956 |
| /2015/04/tika/ | 2.1 |
| /2015/07/parallel-and-concurrent-programming-in-haskell/ | 1.312 |
| /wp-admin/post.php?post=5964&action=edit | 1.114 |
| /wp-admin/post.php?post=5964&action=edit&message=1 | 1.098 |
+-----------------------------------------------------------+--------------------+
DrillからMongoDBにアクセス
drill-embeddedの場合, Drill UI にアクセスして, mongoを Enableに設定する。
下記のようなスキーマで MongoDBに東京ディズニーランドのアトラクションのデータが保存されているとする。
{
"_id" : ObjectId("56073ce6a7f0c24b6b67c2ee"),
"date": "2015/09/27-09:30:19",
"data": [
{
"category": "ワールドバザール",
"name": "オムニバス",
"updated_at": "2015/09/27-09:30:23",
},
{
"category": "ワールドバザール",
"name": "ディズニーギャラリー",
"updated_at": "2015/09/27-09:30:53",
},
{
"category": "ワールドバザール",
"name": "ディズニードローイングクラス",
"updated_at": "2015/09/27-09:31:23",
}
...
]
}
mongo.db.`collection` でアクセスできる。配列に対しては FLATTENが使える。
0: jdbc:drill:zk=local> SELECT d['name']
FROM (SELECT FLATTEN(data) AS d FROM mongo.asset.`tdl_attraction`)
WHERE d['category'] = _UTF16'ワールドバザール' AND d['updated_at'] BETWEEN '2015/09/27-0:00:00' AND '2015/09/28-0:00:00';
+-----------------+
| EXPR$0 |
+-----------------+
| オムニバス |
| ディズニーギャラリー |
| ディズニードローイングクラス |
...
+-----------------+
おまけで, Drillで集計した, ある日の東京ディズニーランドのアトラクション別待ち時間をグラフ化してみた。
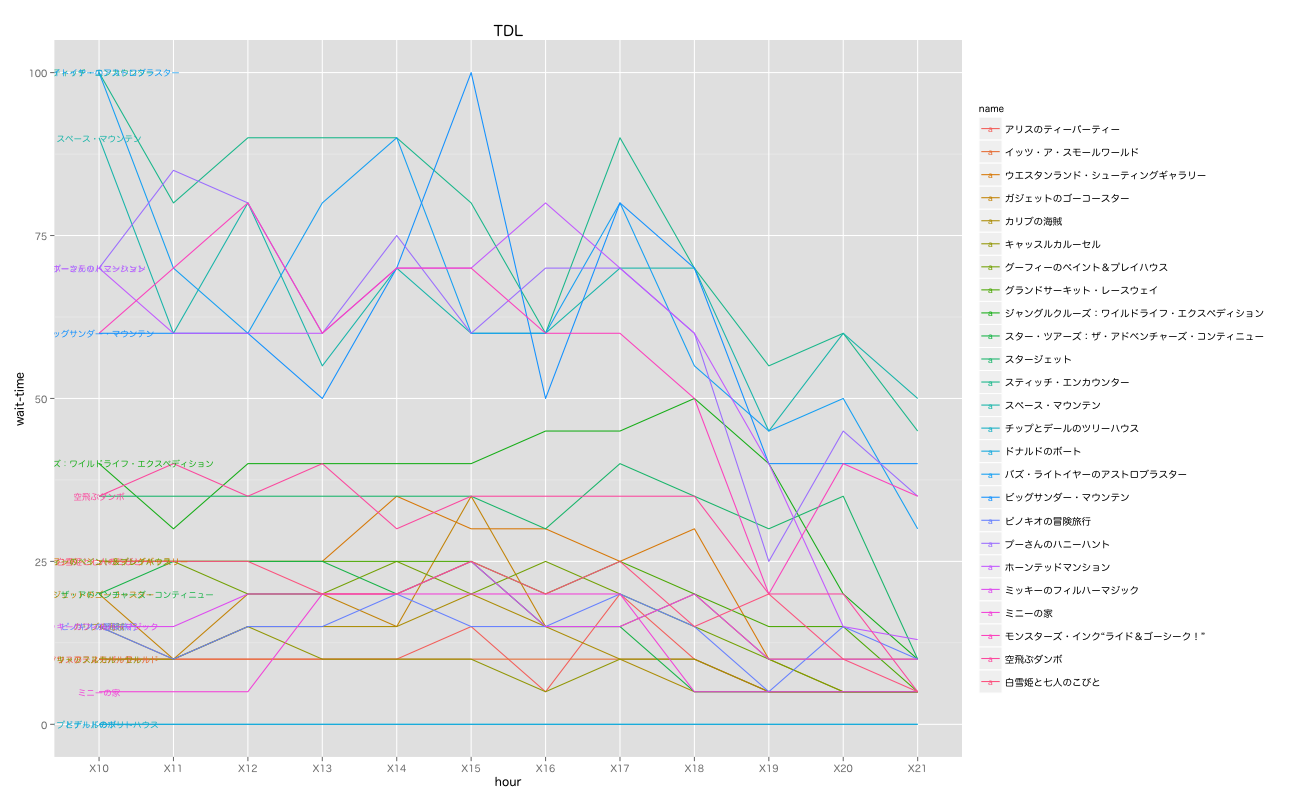
おわりに
某社では, アクセスログを分析して時間がかかっているAPIエンドポイントの処理をチューニングしているようです。
アクセス回数が多くて時間がかかっているエンドポイントをチューニングしていくことが効率的には良いのですが, 偶然サーバがダウンしてしまった等の理由で発生する外れ値 (outlier)によって, 平均値(AVG)や最大値(MAX)は影響を受けてしまいます。
従って, WINDOW関数を使って95%パーセンタイル等を確認するほうが良いとのことです。[1]
[1] Apache Drillで 身の回りのログを集計してみる by acidlemon
[2] Apache DrillでnginxのLTSVログにドリドリとSQLを投げつける – beatsync.net
[3] JSON Data Model