Kaggleとは
“Kaggleは企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である”
アカウント作成からコンペ参加までの流れ
Sign Upから登録を行います。SNS連携はYahoo, Facebook, Google+を選択できます。
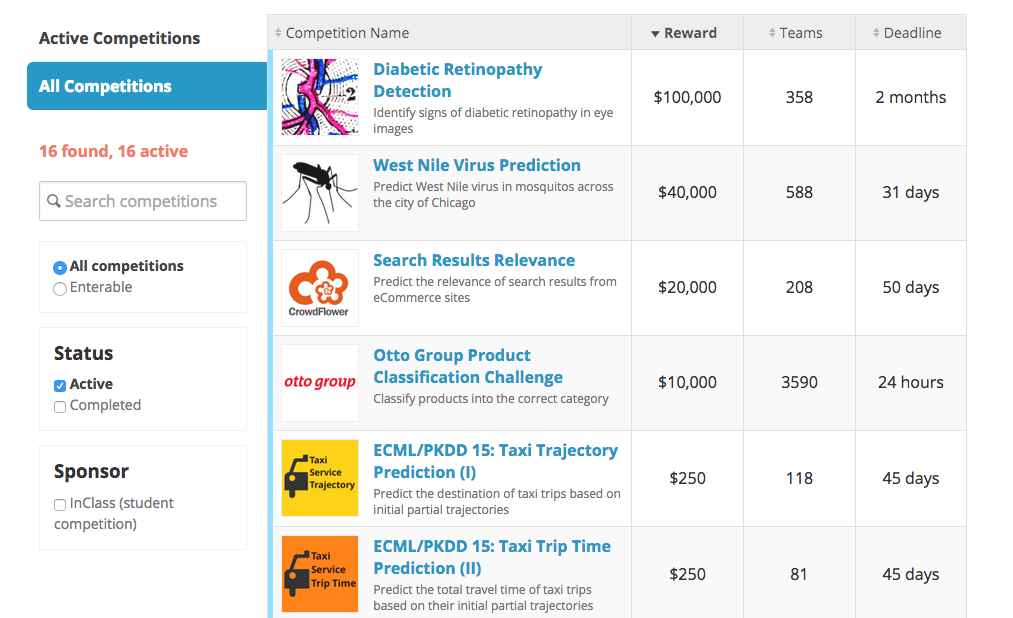
TOPページで, competitionsを選択すると公開されているコンペ課題が表示されます。
個々のコンペを選択すると, Competition Details, Get the Data, Make a submissionの3つのタブが表示されます。
Competition Details
コンペ課題の詳細。Endsは締め切りなので要確認。Points(ユーザランク), Tiers(称号)の説明あり。
Get the Data
学習用データ, 評価用データ, サンプル提出データが手に入る。Data Fieldsは各特徴量の説明。
あるコンペ課題に対して初めてデータを入手する際には, “You must accept this competition’s rules before you’ll be able to download data files.” と確認がでるので同意を行う。
Make a submission
作成したモデルによる予測データの提出。フォーマットはGet the Dataで入手したサンプル提出データを参考にする。
Make a submissionを初めて選択すると, myself(自身だけ)とteamを選ぶ画面に遷移する。
teamを選択したことはないですが, myselfで登録して後にteamに加わることもできるようです。
このタイミングかは忘れましたが, 初めてデータを提出する場合は携帯電話の番号を促されるので, 入力すると携帯に確認コードが届き, 受け取った確認コードを入力するverificationを行う必要があります。
実際にデータを提出すると, リアルタイムに精度の測定が行われ順位とスコアが表示されます。
コンペ参加までの流れは以上です。
下記はBike Sharing Demandという比較的参加チームの多いコンペ課題を見てみます。
Bike Sharing Demand
Bike Sharing Demandは, ワシントンD.Cの自転車シェアリングシステムで1hに何台の自転車が貸し出されるかを予測する問題。
データの説明は下記で, これらの特徴量を活用して予測モデルを構築します。
datetime - hourly date + timestamp
season - 1 = spring, 2 = summer, 3 = fall, 4 = winter
holiday - whether the day is considered a holiday
workingday - whether the day is neither a weekend nor holiday
weather - 1: Clear, Few clouds, Partly cloudy, Partly cloudy
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
temp - temperature in Celsius
atemp - "feels like" temperature in Celsius
humidity - relative humidity
windspeed - wind speed
casual - number of non-registered user rentals initiated
registered - number of registered user rentals initiated
count - number of total rentals
Get the Dataで入手したsampleSubmission.csv(予測値が全て0のデータ)をそのままsubmitすると2960位でスコアは4.76189でした。
お試しで datetime の hour を 3h ごとにクラスに分類する処理を行い time_class として, これを使って RF で予測してみました。
forest <- randomForest(count ~ time_class + temp + season + holiday + workingday + weather + windspeed + humidity,
data=bike.train, ntree=500, proximity=TRUE)
このモデルでスコア0.82366になりました。予測精度が上がるとそれに伴い順位とスコアが上がっていく楽しみがあります。
scriptをForumに公開している人もいるので, 参考にすると良いと思います。
[1] A simple model for Kaggle Bike Sharing.
[2] Kaggle のランキング - tks のメモ