Word2vec は単語の分散表現を作ることができます。分散表現とは単語を固定長の実数ベクトルで表現することです。one-hot encoding は語彙数と等しい次元数の大きさの疎な表現になりますが, 分散表現は密な表現が得られます。
word2vec
Word2vec には CBOW, Skip-gram の2つのアーキテクチャがあります。
CBOW
CBOW (Continuous Bag-of-Words) は単語周辺の文脈から中心の単語を推定します。
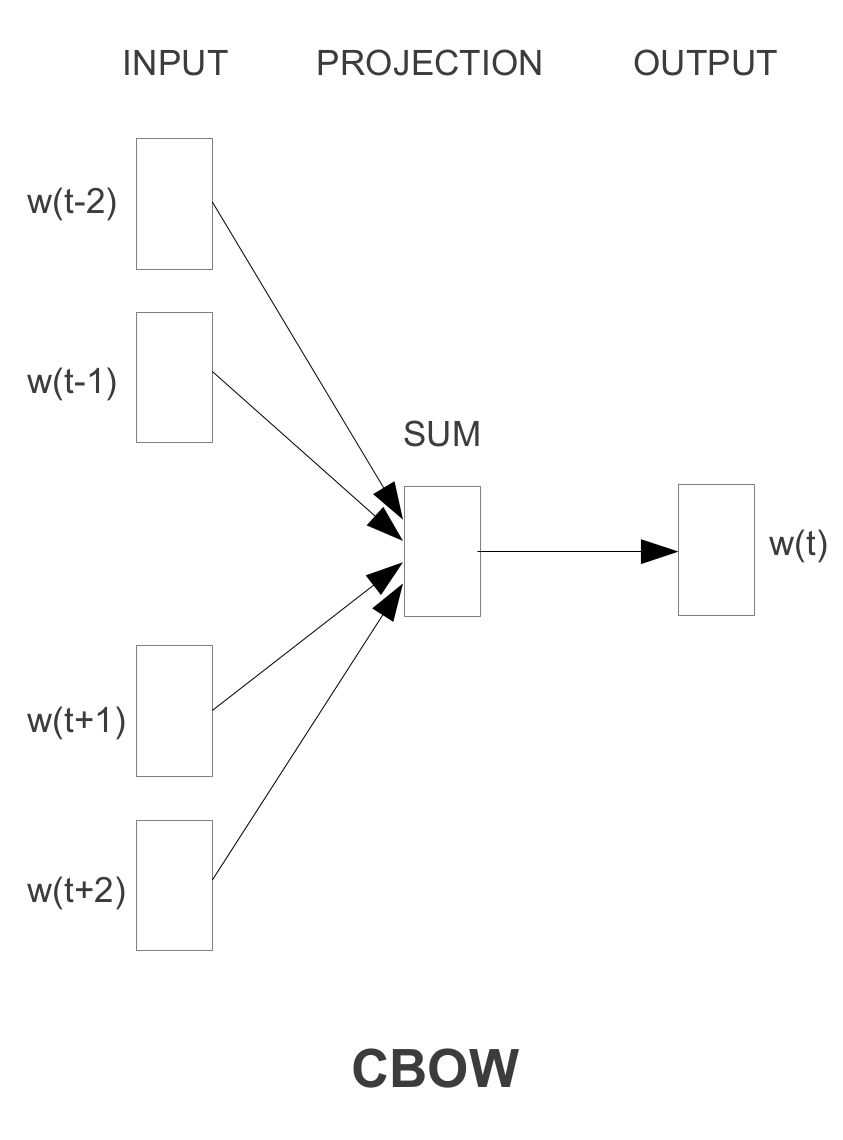
着目している単語の前後計 n 単語を文脈として入力して, 着目している単語 (Wt) を推定します。Skip-gram と比較し高速です。
Skip-gram
Skip-gram は CBOW とは逆で, 中心の単語からその文脈を構成する単語を推定します。単語と文脈をデータからランダムに選択することで容易に負例を生成でき, 正例と負例を分類する分類器を学習させます。この時に隠れ層の入力データの特徴を低次元で表現したベクトルを取り出します。イメージとしては主成分分析が近いと思います。
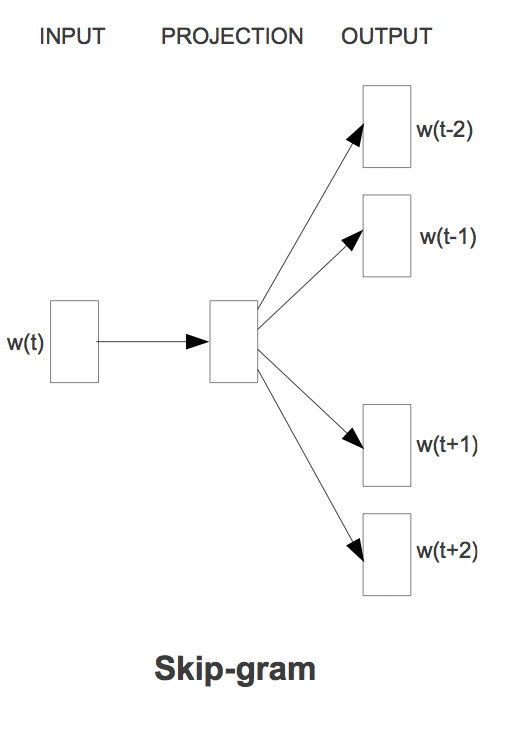
真面目に行列計算すると膨大な計算量になるので, 巨大な行列の一部を取り出して近似計算する低ランク近似というテクニックを使っています。CBOW と比較し低頻度語の予測に優れています。
word2vecを使ってみた
ビルドしてみます。
$ svn checkout https://word2vec.googlecode.com/svn/trunk/
$ mv trunk word2vec
$ cd word2vec
$ make
demo-word.sh を実行すると, text8(100MB) コーパスがダウンロードされ学習が行われます。コーパス (corpus) とは自然言語の文章を構造化し大規模に集積したものです。
Word2vecではコーパスは単語が空白で区切られている必要があります。
make
if [ ! -e text8 ]; then
wget https://mattmahoney.net/dc/text8.zip -O text8.gz
gzip -d text8.gz -f
fi
time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
./distance vectors.bin
単語を入力すると, コサイン類似度の高いベクトルを持つ単語が返ってきます。cat に対してcats, meow や dog とのコサイン類似度が高い結果になっています。
Enter word or sentence (EXIT to break): cat
Word: cat Position in vocabulary: 2601
Word Cosine distance
------------------------------------------------------------------------
cats 0.605998
meow 0.602036
feline 0.573345
purebred 0.560103
dog 0.538197
eared 0.537652
kitten 0.528095
tabby 0.498657
felis 0.494592
caracal 0.492118
rabbits 0.490739
marten 0.488468
dogs 0.487539
possum 0.485236
longhair 0.479865
bobcat 0.475431
lemurs 0.474921
tapir 0.472344
poodle 0.471161
squirrel 0.459128
lynxes 0.457330
nermal 0.454850
shorthair 0.454715
panthera 0.453285
polydactyl 0.451945
bobtail 0.451319
angora 0.447538
felines 0.446365
whiskers 0.445059
proboscis 0.442740
pinnipeds 0.440688
pets 0.440674
crackers 0.440406
greyhounds 0.439546
earless 0.438626
hyena 0.438582
cute 0.438236
canidae 0.436735
badger 0.436714
pet 0.436099
単語の横の数字はコサイン類似度 (Cosine distance) で2つの単語のベクトル表現を長さが1になるように正規化し内積を取ったものです。2つのベクトルのなす角のコサインは内積を取ったものと同じであり、内積を取るとはどれくらい似ているかを計算していることを意味します。
SSL に対しては tls, ssh, authentication など意味的に近い単語が返ってきました。
Enter word or sentence (EXIT to break): ssl
Word: ssl Position in vocabulary: 24088
Word Cosine distance
------------------------------------------------------------------------
tls 0.684158
telnet 0.649690
udp 0.601463
imap 0.590326
ssh 0.583786
tabbed 0.579423
smtp 0.568143
authentication 0.553215
auth 0.546041
server 0.536989
https 0.525759
tcp 0.517657
dhcpv 0.516950
protocol 0.514705
protocols 0.506591
firewall 0.505486
pdh 0.503662
ldap 0.502933
router 0.502890
ipv 0.502163
kerberos 0.501539
icmp 0.500359
sendmail 0.496557
reassembly 0.495496
ftp 0.491670
vpns 0.489015
routers 0.486590
nfs 0.480569
activex 0.480563
appletalk 0.477601
ext 0.474375
khtml 0.474227
mpls 0.474080
firewalls 0.472816
interoperable 0.472784
urls 0.471790
interoperability 0.471413
plugins 0.470373
djbdns 0.470031
ip 0.465974
単語ベクトルの加算・減算をしてみます。
$ ./demo-analogy.sh
3つの単語を入力します。
Enter three words (EXIT to break): tokyo japan paris
Word: tokyo Position in vocabulary: 4915
Word: japan Position in vocabulary: 582
Word: paris Position in vocabulary: 1055
Word Distance
------------------------------------------------------------------------
france 0.650050
french 0.456825
italy 0.452975
germany 0.450363
versailles 0.448568
v(“good”) – v(“best”) + v(“bad”) で worst が返ってきます。
Enter three words (EXIT to break): good best bad
Word: good Position in vocabulary: 385
Word: best Position in vocabulary: 299
Word: bad Position in vocabulary: 1869
Word Distance
------------------------------------------------------------------------
worst 0.488443
oscars 0.440677
bafta 0.440473
cate 0.435084
fondly 0.434065
biggest 0.418510
日本語コーパス
wired.jp の RSS-feed に含まれる記事の単語を Word2vec を使い分散表現を学習させてみます。
$ curl wired.jp/rssfeeder/?count=1000 > in.txt
日本語を単語ごとに分解 (-Owakati) するために, 今回は日本語の形態素解析器である Mecab を使います。
$ sudo apt-get install mecab mecab-naist-jdic python-mecab
前処理として xml から titile タグと description タグだけ抜き出し MeCab で形態素解析しました。
# -*- coding: utf-8 -*-
from BeautifulSoup import BeautifulSoup
import MeCab
def wakati(text):
t = MeCab.Tagger("-Owakati")
m = t.parse(text)
return m
def extract(data):
soup = BeautifulSoup(data,convertEntities="xml")
li = []
for d in soup.findAll("title"):
for c in d.contents:
li.append(c)
for d in soup.findAll("description"):
for c in d.contents:
li.append(c)
return "".join(li)
def main():
f = open("xml/in.xml")
data = f.read()
f.close()
text = extract(data)
res = wakati(text.encode("utf-8"))
f = open("corpus-ja.txt", "w")
f.write(res)
f.close()
print "corpus-ja generated"
main()
結果はさすがに記事全文でないことや, 整形後のデータが 407kB と小さいのでいまいちでした…
Enter word or sentence (EXIT to break): ウェアラブル
Word: ウェアラブル Position in vocabulary: 805
Word Cosine distance
------------------------------------------------------------------------
風力 0.999879
m 0.999878
約 0.999874
ソニー 0.999870
提案 0.999870
する 0.999867
Tango 0.999864
モデル 0.999864
とき 0.999863
魅力 0.999862
アイデア次第で面白いものが作れそうです。
詳しくは参考書籍である『word2vecによる自然言語処理』をご覧下さい。
[1] 言語モデル入門
[2] word2vec playground
[3] MeCabの使い方
[4] NIPS2013読み会でword2vec論文の紹介をしました
[5] word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
[6] Distributed Representations of Words and Phrases and their Compositionality