IT業界でスペシャリストを目指して生きていくのは厳しい時代になってきたのかもしれません。
この技術に詳しければ一生食えるというのはないですし, 10年いや5年でさえわかりません。例えるならゲリラ地帯です。槍の使い方を必死に覚えても, 銃で攻撃されてしまったら勝てません。
スペシャリストから分野を限定せずに, 何でも吸収できるゼネラリストでスペシャリストを目指していかないといけないのかもしれません。

マスコットキャラのペンギンはTuxと言うらしいです。
そもそも組み込み用途でLinuxは必要か
現代的な様々なアプリケーションをゼロから実現しようとすると非常に大変です。しかし, Linuxの場合多くのOSSを利用し比較的容易に実現することができます。
一方で, 実現したいことがリアルタイム処理に特化したことであれば, OSを使わない方が良いかもしれません。
OSが動く分だけメモリも消費しますし, 割り込みの応答速度もプロセスの切り替えやコンテキストスイッチによって遅くなります。
ARMプロセッサであれば純正のリアルタイムOS RTXを使うという選択肢や, OSを使わないでARMのMMUの設定を変更して仮想アドレスと物理アドレスを一致させてマイコンのように使用する方法があります。
しかし, ARMは仮想アドレスを実現するために必要なMMUを搭載していることや, RISC[2]という命令セットアーキテクチャであることからLinuxを動かすには適していると言えます。
LinuxKernelとその開発手法
LinuxカーネルはOSのコア部分でバザールと呼ばれる手法で開発が行われています。最終的には, 各機能ごとの責任者とlinusさんによって管理されているようです。
近年では, Linux Foundationはモバイルおよび組み込みシステムの企業 (Samsung, TI, Linaro)が増えてきており, また主要メンテナはRed Hat, Intel, Google等の大企業が名を連ねています。
linusさんによってcommitされたパッチは3.0以降は, 1%未満となっているようです。
また, kernelのソースコードはlinusさんによって開発されたGitというバージョン管理ソフトで管理されています。
Gitリポジトリはkernel.orgにあります。
Kernelの機能
Linuxカーネルの基本的な機能を大きく, 7つに分類してみました。
- メモリ管理
- プロセス管理
- プロセススケジューリング
- ネットワーク
- デバイス管理
- I/Oスケジューリング
- ファイルシステム
I/Oやネットワーク, デバイスドライバという主要な機能をカーネルのメモリ空間と同じ場所に配置しようというのがLinuxを含むUNIXに代表されるモノシリックカーネル [1]の設計思想です。
メモリ管理
メモリ管理はページング方式が採用されています。
LinuxはH/W要件として, CPUにMMU (memory management unit)が搭載されている事が条件となります。
主要なCPUアーキテクチャ, 例えばARMにはMMUが搭載されています。MMUでは論理アドレスと物理アドレスを変換するページテーブルがあります。この変換処理を効率化するためにMMUには, TLB (Translation Lookaside Buffer)と呼ばれるキャッシュが搭載されています。
カーネルは起動時にMMUのページテーブルを書き換えます。
プロセス管理
プロセスは, Linux上で動作するアプリケーションを指します。
全ては initという起動時に呼ばれるプロセスの子プロセスとして展開されます。全てのプロセスには Process ID (PID)が付与されます。PID以外にもSession ID (SID)などひとつのプロセスに複数のIDが付与されます。
プロセススケジューリング
CPUに割り当てるプロセスを切り替える方式です。Completely Fair Scheduler (CFS) [3]という, 過去に使用したタスク時間の短いタスクに優先的に処理を割り当てるスケジューリング方式が2.6.16で導入されました。その後も, カーネルの進化と共にスケジューリング方式も変わってきています。
ネットワーク
通信を行う上ではネットワークプロトコルや通信相手の指定が必要になります。そのために, Socketというインターフェイスが用意されています。
Socketで繋がるという機能をOSレベルで持っていることUNIX, Linuxが普及した理由のひとつではないかと思います。リリースごとに変化はしていますが, 何度も変化してきたI/Oスケジューリング等と比較すると, この機能は昔から安定しているのではないでしょうか。外部との通信の仕組みは, Linuxの TCP/IP実装 [4]が参考になります。
デバイス管理
デバイスはファイルに抽象化されています。これをデバイスファイルといい/dev以下に配置されます。
例えば, HDDなら /dev/sda となります。デバイスにはキャラクタ型とブロック型があります。
キャラクタはターミナルのように 1Byteずつ処理するデバイスで, ブロック型は固定長のブロック単位で処理するタイプです。
I/Oスケジューリング
I/Oスケジューリングは名前の通り, 様々なデバイスとの通信を制御します。
いかに効率よくリソースを使うかという観点で, H/Wの進化と共にLinuxのI/Oスケジューリング方式も変化してきました。
ファイルシステム
Linuxのファイルシステムには ext4を初め複数のファイルシステムに対応しています。
ユーザプログラムがfopen(3)などでファイルを開いたりする場合でも、VFS (virtual file system)で抽象化することで, 異なるファイルシステムに対してユーザ側のプログラムを変更せずに済むような仕組みとなっています。VFSは異なるコンテキストからのアクセスを実現するために関数ポインタで実装されているようです。
Linuxはデバイスさえファイルとして管理します。プロセスからのファイルシステムへのアクセスはStreamと呼ばれるバイト列のネットワークで繋がります。
コンテキストとは
コンテキストとは, カーネル内の処理の発生源とそれから生じる流れを指します。
コンテキストという視点でカーネルを考えてみることで, 障害発生時の原因を特定するカギを掴めるかもしれません。
コンテキストは大きく, ユーザコンテキストと割り込みコンテキストに分類できそうです。
ユーザコンテキスト
read(2)やwrite(2)などはシステムコールと呼ばれ, ユーザ空間から呼び出されるカーネルへのインターフェイスとなります。
このシステムコールから続く処理が, ユーザコンテキストです。
割り込みコンテキスト
割り込みハンドラからの一連の処理は, 割り込みコンテキストと呼ばれます。
H/Wからの割り込みやタイマ処理などからの流れが割り込みコンテキストです。
カーネルは様々なアプリケーションやH/W割り込みによるアクション (イベント)を待つ, Slave的な存在と言えます。
カーネル空間内ではメモリが共有されるので, 1つのリソースを複数のコンテキストからアクセスされる場合, 競合が発生することが懸念されます。従ってカーネルはリソースへのロック機構を有しています。
カーネル空間の資源に対してのアクセスをシステムコールに限定しないとシステム全体の安定性に影響を及ぼしてしまいます。
従って, 秩序を守るためにユーザ空間 (User Land)からカーネル空間の機能に直接アクセスすることは推奨されません。
システムコールの流れ
Linuxでは前述したメモリ空間の分離だけでなく, CPUもカーネルモードとユーザモードで分離しています。
システムコール[5]の仕組みを少し追ってみます。ユーザ空間からシステムコール関数を呼ぶと, libcが内部で syscall()によってカーネル側に処理が移ります。
long syscall(long number, ...);
カーネルは, システムコールハンドラ内でシステムコールごとに割り振られた numberで処理を振ります。例えば, read(2)は0, write(2)は1といった具合です。
システムコールハンドラによって呼ばれる関数は全て prefixとして sys_が付与されています。
カーネル内での処理が終了し, ユーザ空間に処理を戻す場合はカーネル内で sysret()が呼ばれ libcに処理が戻り, エラーの場合は libc内で適切なerrnoが設定されます。
一方で, カーネル内部の状態を変化させないシステムコール, 例えば 時刻を取得するgettimeofday(2)の場合は vDSO (Virtual Dynamic Shared Object)という仕組みにより, カーネルのメモリをread-onlyでユーザ空間のメモリにmapします。これによって, コンテキストスイッチによるCPU時間の消費を削減しています。
Kernelの仕組みについて, さらに興味がある人は専門書やソースコードを読まれることをオススメします。
LinuxKernel起動までの仕組み
HDDからlinuxが起動するまでの流れを見てみます。
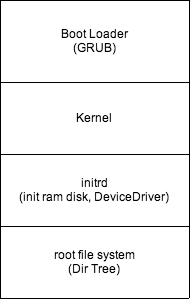
OSはブートローダから呼ばれます。MBR (Master Boot Record)という領域にブートローダがあり, ROMからvmlinuz (非圧縮ELFバイナリ), または圧縮バイナリ (zImage等) を展開し memcpy(3)で特定のメモリ番地にjumpします。起動は展開を行わない非圧縮バイナリの方が速くなります。
次に initrdというファイルが呼ばれ, HDDをマウントするデバイスドライバによってルートファイルシステムが利用可能になります。
そして, /sbin/initプロセスから各種プログラムが起動します。例えば, /etc/initや /etc/rc5dに設定を書きます。
ARMボードによる例
ARMボード上で, Linuxを起動させるまでの構成例です。

Kernel再構築
組み込み用途ではデスクトップ用Linuxディストリビューションと比較してリソースに制限がある場合が多いことから, 使う機能を限定したい時があります。そのようなKernelが提供するある機能は欲しいけど, 別のある機能はいらないというときは, 以下のコマンドでKernelを再構築します。
$ make menuconfig
設定が完了すると /linux/.configが更新されます。
$ make linux
以下のようなエラーの場合, u-boot-tools をインストールして mkimage を使えるようにします。
"mkimage" command not found - U-Boot images will not be built. "
ビルドが終わると, /linux/arch/arm/boot/に下記のカーネルイメージが生成されます。
- zImage : gzipで圧縮されたカーネルイメージ
- uImage : U-Bootでブートされるイメージ
- vmlinux : 非圧縮のカーネルイメージ
生成されたカーネルイメージを用いてLinuxをブートするには, ブートローダが必要になります。
U-Boot
Windowsで馴染みのある BIOSはこのブートローダの機能です。
デスクトップ用Linuxディストリビューションでは x86向けの GRUBが有名ですが, 組み込み用途では下記の理由でU-Bootが使われることが多いようです。
- 組み込み向けの多様なアーキテクチャに対応
- RAMの初期化 (ルートファイルシステムのマウント)
- メモリのレジスタにデフォルト値を設定
まず, U-BootをビルドしてCPU内蔵フラッシュROMに書き込みます。U-Boot環境変数でどこからブートするかを設定します。
U-Bootはhush (busyboxのshell)に対応しておりコマンドラインで操作できます。
$ printenv
bootcmd=nand read.e 0x800000 0x100000 0x400000; bootm 0x800000
U-Bootの場合ですがROMから起動する場合は setenvで設定します。
$ setenv bootcmd 'nand read.e 0x800000 0x100000 0x400000; bootm 0x800000'
$ saveenv
正常にLinuxが起動すると, RHEL, DebianなどのLinuxディストリビューションと同様に, FHS (Filesystem Hierarchy Standard)に準拠したディレクトリ構成となっていることが確認できます。これは重要な点で, ユーザが存在を認識していない機能やファイルは使うことはできないため, どこに何のファイルが存在しているかを推測し易くなっているのは大事なことです。
TFTPサーバ
TFTPはUDPを用いてコンピュータ間でファイルを転送するためのプロトコルです。FTPに比べて軽量・単純なプロトコルなのが特徴です。
カーネルイメージをTFTPでターゲットデバイスにネットワーク転送するようにします。
$ apt-get install tftpd-hpa
設定ファイルは /etc/default/tftp です。 /var/lib/tftpboot/に設定してuimageを配置します。
U-Bootの環境変数にTFTPクライアントの設定をします。
$ setenv bootcmd 'tftp 0xc0700000 uImage; tftp 0xc1180000 ; bootm 0xc0700000'
$ saveenv
デーモン化しておくと便利かもしれません。
Defaults for tftpd-hpa
RUN_DAEMON="yes"
OPTIONS="-l -s /var/lib/tftpboot"
再起動します。
# xinetdの場合あり
$ /etc/init.d/tftpd-hpa restart
NFSマウント
NFS (Network File System)は, 主にUNIX系で使われている分散ファイルシステムです。
HDDの場合は通常、パーティション分割してファイルシステムを作ってからマウントする事で読み書きが可能になります。
NFSを使うことで簡単にホストマシンとファイル共有ができるようになり, 手軽にアプリケーションをボード上で試すことができます。
NFSサーバの任意のディレクトリをボードのRAMにマウントします。
$ apt-get install nfs-kernel-server
/etc/exports でNFSを許可するマシンとmount対象のディレクトリを設定します。
/path/to/your/directory 168.192.7.2/255.255.255.0(rw,no_root_squash)
再起動して反映させます。または exportfs -ra です。
$ /etc/init.d/nfs-kernel-server restart
ターゲットデバイスでマウントポイントを作成して mountを行います。
$ mkdir ./mfs
$ mount -t /path/to/your/directory ./mfs -o nolock
次回は, Linuxデバイスドライバについて書きます。
[1] Linuxがモノリシックカーネルである理由
[2] 元々,RISC開発背景にUNIX向け高性能プロセッサの提供が目的のひとつであった
[3] 【CPU】Linuxのプロセススケジューラの基礎【CFS】
[4] TCP Implementation in Linux: A Brief Tutorial
[5] kernel 3.15時点では, 317個のシステムコールが定義されているようです。