『実証分析入門 データから「因果関係」を読み解く作法』の 10章 バイアス について R でトレースしてみます。
バイアスをシミュレーションで確認する
10章 バイアス では例題として, ある世界の真の状態が以下の式で表せると仮定している。

観察者は事前にこれを正しいモデルであるとは知りえない。
この真のモデルに到達できない場合は下記の2パターンが考えられる。
- 間違って無関係な説明変数を組み込んでしまう (1)
- 間違って必要な説明変数を落としてしまう (2)
上記の数式からランダムに100個のサンプルを生成する。本書に倣い, 教育年数と能力にはある程度の相関を仮定しているので, 母相関を 0.8 に設定する。
generate_data <- function(n) {
rho <- 0.8
x <- rnorm(n, mean = 4, sd = 2)
e1 <- rnorm(n, mean = 12, sd = 3)
e2 <- rnorm(n, mean = 9, sd = 3)
education <- sqrt(rho) * x + sqrt(1-rho) * e1
ability <- sqrt(rho) * x + sqrt(1-rho) * e2
salary <- 50 + education*2 + ability*0.8 + rnorm(n, mean = 0, sd = 3)
# unrelated variable
garbage <- rpois(n, lambda = 2)
df <- data.frame(y = salary, x1 = education, x2 = ability, x3 = garbage)
return(df)
}
この生成したデータを使って, 線形回帰で正しいモデル, 間違ったモデルの推定値を求める。各モデルで 1,000回繰り返し, 推定値の分布から平均を求める。 (本書では10,000回)
標本抽出を繰り返した時 (上記例での1,000回) に推定値の平均が母集団のパラメータと一致する性質を 不偏性 (unbiasedness) という。
似た概念に 一致性 (consistency) があり, こちらは標本サイズを大きくした場合に推定値の平均が次第に母集団のパラメータに近づく性質 [1]である。
間違って無関係な説明変数を組み込んでしまう (1) 場合のシミュレーションでは, 賃金とは無関係な変数を説明変数に組み込んでおり, 無益であるが害はほとんどないと考えられる。(事前知識で無関係と判断できるならわざわざ残す必要もない)
また, 間違って必要な説明変数を落としてしまう (2) 場合のシミュレーションでは, 必要な説明変数である能力を外しているため, 欠落変数バイアス (omitted variable bias, OVB) [2]が確認できるはずである。
build_true_model <- function(n) {
df <- generate_data(n)
model <- lm(y ~ x1 + x2, df)
return(model$coefficients)
}
build_false_model1 <- function(n) {
df <- generate_data(n)
model <- lm(y ~ x1 + x2 + x3, df)
return(model$coefficients)
}
build_false_model2 <- function(n) {
df <- generate_data(n)
model <- lm(y ~ x1, df)
return(model$coefficients)
}
res1 <- lapply(mapply(rep, 1:1000, 0), function(x) build_true_model(100))
coef.true <- cbind(data.frame(t(data.frame(res1))), x3 = 0, model = "true (x1 + x2)")
res2 <- lapply(mapply(rep, 1:1000, 0), function(x) build_false_model1(100))
coef.false1 <- cbind(data.frame(t(data.frame(res2))), model = "false (x1 + x2 + x3)")
res3 <- lapply(mapply(rep, 1:1000, 0), function(x) build_false_model2(100))
coef.false2 <- cbind(data.frame(t(data.frame(res3))), x2 = 0, x3 = 0, model = "false (x1)")
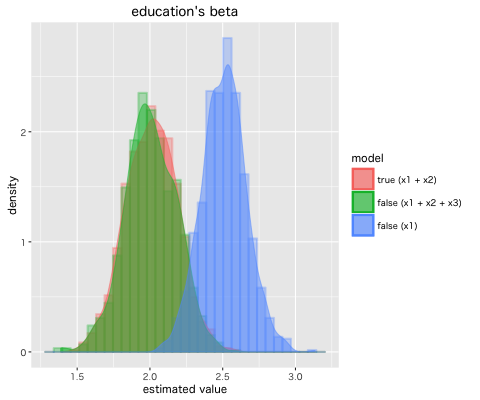
各モデルでの教育年数の偏回帰係数 β1 の推定値の分布は下記となった。
推定値の分布から統計量を求める。
coef <- rbind(coef.true, coef.false1, coef.false2)
coef.stat <- coef %>% group_by(model) %>% summarise(
X.Intercept.mean = mean(X.Intercept.),
X.Intercept.var = var(X.Intercept.),
x1.mean = mean(x1),
x1.var = var(x1),
x2.mean = mean(x2),
x2.var = var(x2),
x3.mean = mean(x3),
x3.var = var(x3)
)
必要な説明変数を落としたモデルは, 平均 2.51 と真のモデルの平均 2.01 と比較して欠落変数バイアスが発生していることがわかる。
また, 推定された定数項 β0 の分布は下記となった。
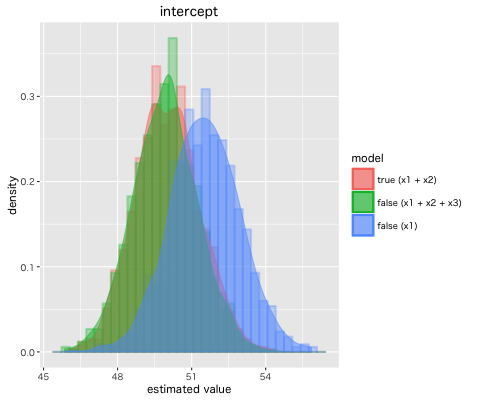
今回確認した バイアス (Bias) への対処として, 代理変数 (proxy variable)を使うことが挙げられる。上記例で言うと能力という説明変数は通常, 観測できるデータではないのでIQを使うことが考えられる。ただし, IQは能力に一致するわけではないので推定値にバイアスが発生するが, 欠落変数バイアスよりは小さいバイアスとなるので, 使わないよりは良いモデルになり得る。
どの程度バイアスが小さいかを測るのは代理変数との相関を求めれば良さそうだけど, 能力のような数値化が困難な場合は難しそうだ。
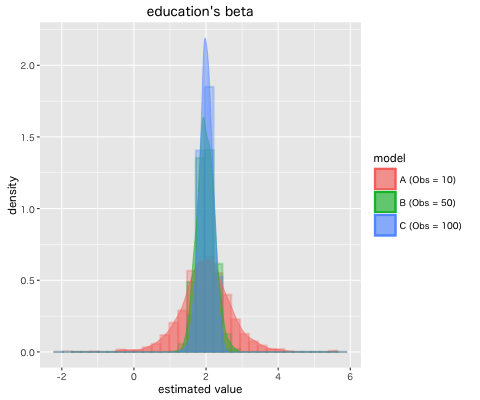
ついでに, 正しいモデルで 標本サイズ n を 10, 50, 100 と変えていくとパラメータの推定値の分散が 0.498, 0.060, 0.033 と小さくなること [4] を確認した。
測定誤差・欠測データ・外れ値
10章 バイアス では, 測定誤差・欠測データ・外れ値への対処にも触れられているので要約しておく。
- 測定誤差 (measurement error) : 目的変数の測定誤差は, 説明変数と相関していなければバイアスにはならない
- 欠測データ (missing data) : 欠測が完全にランダムではなく, システマチックに起きている場合は問題となる
- 外れ値・異常値 (outlier) : まずは入力ミス等を疑う。外れ値の原因が特定できない場合は, 除外せずに分析を進める
おわりに
コードを書いた後に本書のソースコードの存在 [5] に気づきました。人工データの生成はそちらを参考にしてください。
本書は実証分析自体には興味がなくても, 統計分析の入門書としても分かりやすい本だと思います。

[1] パラメータ推定方法の良しあしの基準として, 既に挙げた不偏性, 一致性 以外にも, 有効性, 漸近正規性, 十分性がある。詳しくは統計的学習理論(1): フィッシャー情報量とクラメールラオ下限と最尤法を参考に。
[2] 教育年数と能力に相関がない又は賃金と能力に相関がなければ, このバイアスは発生しない。実証分析では, 残された説明変数と省略された説明変数が無相関な場合は少ないのでバイアスはあると考える方が良さそう。
[3] Rで架空データの発生
[4] ある範囲に真のパラメータが存在がする可能性を信頼度といい, 信頼度によって決められる範囲が信頼区間で n が大きくなると信頼区間は 1/√n に狭まる。
[5] 法律家のための実証分析入門