
『Haskellによる並列・並行プログラミング』(原著名: Parallel and Concurrent Programming in Haskell) を読了した。O’Reilly 本は電子書籍に限っては英語版がオススメである。半額割引コードが使えたり, 2冊買うと1冊無料というサービスがあるからである。電子書籍の価格に日米でここまで差があるのは商習慣の違いが大きいと思っている。日本語版の利点としては appendix が追加されることがある点がある。
今回はI部までのCodeをトレースした。Codeは主に parconc-examplesを参照した。
OSは OSX10.10, ハードウェア環境は以下。
$ system_profiler SPHardwareDataType
Hardware:
Hardware Overview:
Model Name: MacBook Air
Model Identifier: MacBookAir5,1
Processor Name: Intel Core i5
Processor Speed: 1.7 GHz
Number of Processors: 1
Total Number of Cores: 2
L2 Cache (per Core): 256 KB
L3 Cache: 3 MB
Memory: 4 GB
Boot ROM Version: MBA51.00EF.B02
SMC Version (system): 2.4f19
準備としてcabalを updateしておく。
$ cabal update
$ sudo cabal install cabal-install
本書のサンプルコードの取得。
$ cabal unpack parconc-examples
$ sudo cabal install parallel
threadscopeはDebian系なら, apt-getでインストールできる。
OSXの場合には gtk+を用いたインストールする方法もあるが, バイナリも配布しているのでそちらの方が簡単である。
threadscopeの使い方はtutorialを参照。
1章 はじめに
1.1 用語:並列性と並行性
1.2 ツールとリソース
1.3 サンプルコード
並列画像処理, 並行Webサーバなど身近に並列/並行という似ている単語が使われるが, それぞれの定義は下記。
- 並列 (parallel) : 複数のプロセッサで同時に実行
- 並行 (concurrent) : 複数のスレッドで実行
本書によると, スレッドを制御するということは純粋関数プログラミングでは意味を持たない。何故なら, 純粋であるならば観測されるエフェクトが存在せず, 評価順序も重要でないからである。Haskellだと I/Oモナドはエフェクトを持っている。
- 決定的プログラミングモデル : 1つの結果を返すことしか許されない
- 非決定的プログラミングモデル : 実行の状況により異なる結果を返す
外部の世界とのやりとりは予測不可能なため, 並行プログラミングは非決定的であると言える。
並列プログラミングでは可能ならば決定的プログラミングモデルを採用すべき。
2章 基本の並列性:Evalモナド
2.1 遅延評価と弱頭部正規形
2.2 Evalモナド、rpar、rseq
2.3 例:並列数独ソルバ
2.4 Deepseq
本章では並列性を扱う基本的な機能であるEvalモナドを扱う。
- rpar : 並列評価できることの明示
- rseq : 引数の評価が完了するまで待つ
アムダールの法則(Amdahl’s law)は以下で示される。並列化できる部分の実行時間の割合をP, プロセッサのコア数をNとした場合, 並列化の効果は下記となる。

コア数をいたずらに増やして計算させても, それだけでは速度向上に限界があると言えそうだ。
rparを試してみる。-O2で最適化, -threadedで並列性の指定を行う。
$ ghc -O2 rpar.hs -rtsopts -threaded
$ ./rpar 1 +RTS -N2
time: 0.00s
(24157817,14930352)
time: 1.32s
$ ./rpar 2 +RTS -N2
time: 0.83s
(24157817,14930352)
time: 2.18s
$ ./rpar 3 +RTS -N2
time: 2.18s
(24157817,14930352)
time: 2.18s
並列性の例として, 数独を解くプログラムを扱う。まずは単一コアで実験。+RTS -sで統計情報を吐き出す。
$ ghc -O2 sudoku1.hs -rtsopts
$ ./sudoku1 sudoku17.1000.txt +RTS -s
1000
2,328,615,624 bytes allocated in the heap
39,137,760 bytes copied during GC
250,904 bytes maximum residency (14 sample(s))
80,776 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 4506 colls, 0 par 0.10s 0.11s 0.0000s 0.0010s
Gen 1 14 colls, 0 par 0.00s 0.00s 0.0003s 0.0005s
TASKS: 4 (1 bound, 3 peak workers (3 total), using -N1)
SPARKS: 0 (0 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 1.95s ( 1.98s elapsed)
GC time 0.11s ( 0.12s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 2.06s ( 2.09s elapsed)
Alloc rate 1,194,742,687 bytes per MUT second
Productivity 94.8% of total user, 93.2% of total elapsed
gc_alloc_block_sync: 0
whitehole_spin: 0
gen[0].sync: 0
gen[1].sync: 0
Total time がCPU時間, elapsed が経過時間。それぞれ 2.06s, 2.09sとなった。
続いて, 並列化したコードを実行する。eventlogオプションでeventlogを出力するように指定。
$ ghc -O2 sudoku2.hs -rtsopts -eventlog -threaded
[2 of 2] Compiling Main ( sudoku2.hs, sudoku2.o )
Linking sudoku2 ...
$ ./sudoku2 sudoku17.1000.txt +RTS -s -N2 -l
1000
2,336,624,560 bytes allocated in the heap
51,260,304 bytes copied during GC
2,727,488 bytes maximum residency (7 sample(s))
278,088 bytes maximum slop
9 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 2948 colls, 2947 par 0.68s 0.11s 0.0000s 0.0007s
Gen 1 7 colls, 7 par 0.03s 0.02s 0.0022s 0.0038s
Parallel GC work balance: 51.68% (serial 0%, perfect 100%)
TASKS: 6 (1 bound, 5 peak workers (5 total), using -N2)
SPARKS: 2 (1 converted, 0 overflowed, 0 dud, 0 GC'd, 1 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 1.65s ( 1.35s elapsed)
GC time 0.70s ( 0.13s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 2.35s ( 1.48s elapsed)
Alloc rate 1,414,992,097 bytes per MUT second
Productivity 70.2% of total user, 111.6% of total elapsed
gc_alloc_block_sync: 8390
whitehole_spin: 0
gen[0].sync: 1
gen[1].sync: 71
速度向上は 2.09 / 1.48 = 約1.41倍となった。
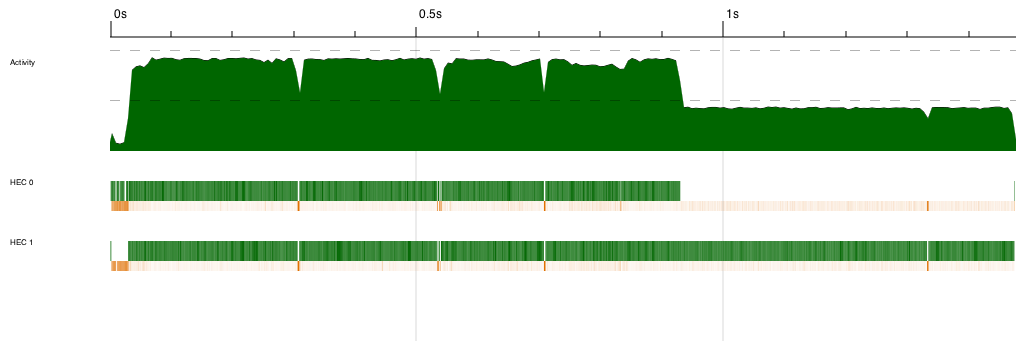
出力されたsudoku2.eventlogをthreadscopeに喰わせる
3章 評価戦略
3.1 戦略の並列化
3.2 リストを並列に評価する戦略
3.3 例:K平均法
3.3.1 K平均法の並列化
3.3.2 性能と分析
3.3.3 スパーク活動の可視化
3.3.4 粒度
3.4 GCされるスパークと投機的並列性
3.5 parBufferを使った遅延ストリームの並列化
3.6 チャンク分け戦略
3.7 同一性特性
Haskellでは評価戦略 (evaluation strategy)に遅延評価を採用している。一方, ほとんどの命令型プログラミング言語では積極評価 (正格評価, 先行評価とも)を採用している。
関数型言語の理論的な背景にはラムダ計算があり, 簡約 (reduction)という変換規則に沿って評価を行う。それ以上, 簡約できない形になることを正規形 (normal form)という。
Haskellでは, WHNF (Week Head Normal Form)まで評価される。[2]
- これ以上適用する値がない関数
- 式の先頭にコンストラクタが出た状態の値
これにより, データ構造の評価タイミングとデータの中身の値の評価タイミングを分離している。構造の評価時に中身の値を評価しないことで, 無限ループを回避するメリットがある。
一方で, 遅延評価では評価が行われないまま放置されているオブジェクトが発生する。これをサンク (thunk)や遅延データオブジェクトと言う。これは, 手続き f()の呼び出しの時に引数は値になる積極評価と比べ, サンクを保持するためにメモリを余分に消費してしまう。
現代のコンピュータアーキテクチャは, 積極評価を前提にされているためか, 積極評価と相性が良いようだ。[3]
Haskellの並列性に関する評価戦略は, 並列性からアルゴリズムを分離して並列コードをモジュール化する手法のことを指す。
この章で扱う, k-means はクラスリングのアルゴリズム。必要なmoduleをインストールする。
$ sudo cabal install normaldistribution
$ sudo cabal install monad-par
BuildはMakefileもあるので, makeでもOK。
$ ghc -O2 -threaded -rtsopts -eventlog kmeans.hs
$ ghc -O2 GenSamples.hs
クラスタを形成するデータを生成して, K-meansでクラスタリングを行う。
$ ./GenSamples 5 50000 100000 1010
$ ./kmeans seq
...
iteration 20
Cluster {clId = 0, clCent = Point (-5.843594657217429) (-5.465023143155277)}
Cluster {clId = 1, clCent = Point 8.316354592277696 (-8.330430847304271)}
Cluster {clId = 2, clCent = Point (-9.06455081846093) 7.561852464109018}
Cluster {clId = 3, clCent = Point 9.24359773112845 6.138576051709859}
Cluster {clId = 4, clCent = Point (-3.6217091143407467) (-1.824581243202074)}
[Cluster {clId = 0, clCent = Point (-5.843594657217429) (-5.465023143155277)},Cluster {clId = 1, clCent = Point 8.316354592277696 (-8.330430847304271)},Cluster {clId = 2, clCent = Point (-9.06455081846093) 7.561852464109018},Cluster {clId = 3, clCent = Point 9.24359773112845 6.138576051709859},Cluster {clId = 4, clCent = Point (-3.6217091143407467) (-1.824581243202074)}]
Total time: 1.20
並列化前のコードは下記。
step :: Int -> [Cluster] -> [Point] -> [Cluster]
step nclusters clusters points
= makeNewClusters (assign nclusters clusters points)
assign :: Int -> [Cluster] -> [Point] -> Vector PointSum
assign nclusters clusters points = Vector.create $ do
vec <- MVector.replicate nclusters (PointSum 0 0 0)
let
addpoint p = do
let c = nearest p; cid = clId c
ps <- MVector.read vec cid
MVector.write vec cid $! addToPointSum ps p
mapM_ addpoint points
return vec
where
nearest p = fst $ minimumBy (compare `on` snd)
[ (c, sqDistance (clCent c) p) | c <- clusters ]
assignはそれぞれの点をクラスタごとに割り当てていく関数で, この部分を並列化する。
parSteps_stratで点のリストをチャンクに分ける。入力データをチャンクに分けることで, 並列性が過度に細粒度化するのを防ぐ
parSteps_strat :: Int -> [Cluster] -> [[Point]] -> [Cluster]
parSteps_strat nclusters clusters pointss
= makeNewClusters $
foldr1 combine $
(map (assign nclusters clusters) pointss
`using` parList rseq)
並列化コードを実行してみる。
$ ./kmeans start 64 +RTS -N2
...
iteration 20
Cluster {clId = 0, clCent = Point (-5.843594657217393) (-5.465023143155272)}
Cluster {clId = 1, clCent = Point 8.316354592277674 (-8.330430847304319)}
Cluster {clId = 2, clCent = Point (-9.064550818461058) 7.561852464109084}
Cluster {clId = 3, clCent = Point 9.243597731128494 6.138576051709921}
Cluster {clId = 4, clCent = Point (-3.621709114340708) (-1.8245812432020834)}
[Cluster {clId = 0, clCent = Point (-5.843594657217393) (-5.465023143155272)},Cluster {clId = 1, clCent = Point 8.316354592277674 (-8.330430847304319)},Cluster {clId = 2, clCent = Point (-9.064550818461058) 7.561852464109084},Cluster {clId = 3, clCent = Point 9.243597731128494 6.138576051709921},Cluster {clId = 4, clCent = Point (-3.621709114340708) (-1.8245812432020834)}]
Total time: 0.73
RSA暗号は有名な公開鍵暗号。OSXだと下記コンパイル エラーが発生。
$ ghc -O2 -threaded -rtsopts rsa.hs
...
error: token is not a valid binary operator in a preprocessor subexpression
Buildは #ifディレクティブをコメントアウトすると通った。
{-# LANGUAGE CPP #-}
module ByteStringCompat () where
import qualified Data.ByteString.Lazy.Char8 as B
import Data.ByteString.Lazy.Char8 (ByteString)
import Control.DeepSeq
-- #if !MIN_VERSION_bytestring(0,10,0)
--
-- instance NFData ByteString where
-- rnf x = B.length x `seq` ()
--
-- #endif
文字列 Hello Worldを渡して, 暗号, 復号をpipeで繋いで, 元の文字列になることを確認。
$ echo "Hello World" | ./rsa encrypt - | ./rsa decrypt -
Hello World
4章 データフロー並列:Parモナド
4.1 例:グラフの最短路
4.2 パイプライン並列
4.2.1 生産者の流量制限
4.2.2 パイプライン並列の制限
4.3 例:会議の時間割
4.3.1 並列性の追加
4.4 例:並列型推論器
4.5 別のスケジューラを使う
4.6 戦略と比較したParモナド
Evalモナドとは異なる並列プログラミングモデルであるParモナドを扱う。
parモナドは, データフロー並列を扱う。並列プログラミングにとって重要な決定性を損なわずに, 明示的にデータの依存関係を記述して遅延評価への依存をなくす。
データフローグラフは nodeと edgeで構成される。
Floyd-Warshallアルゴリズムはグラフの最短経路を求めるアルゴリズムである。頂点数 1000 枝数 800 で試してみる。
$ ghc -O2 -threaded -rtsopts parmonad.hs
Linking parmonad ...
$ ./parmonad 34 35 +RTS -N2
24157817
引数の関数がモナディックな場合, suffixにMをつけるのが習慣のよう。
パイプライン並列化では, ストリームの要素に対するデータ並列ではなくて, パイプラインのステージ間の並列性を利用sる方法を利用する方法を学ぶ。
RSA暗号の例で, 暗号化ストリーム生成し, 復号がそれを消費する。基本的には復号化側は暗号化側より速いので, 次のストリームがくるまで待つ。
送り手 (暗号化側)の方が速いなら, 流量制限をかける必要がある。
$ ghc -O2 -threaded -rtsopts -eventlog rsa-pipeline.hs
$ echo "HelloWorld" | ./rsa-pipeline -
型推論を試してみる。
まず, Haskellの有名なLexer, Parserであるalexとhappyをインストールする。
dependenciesである network, repaの指定された範囲のversionにする。
$ sudo cabal install alex happy
$ sudo cabal install network-2.4.2.3 repa-3.2.5.1
$ cabal repl parinfer/parinfer.hs
*Main> test "1+2"
Int
*Main> test "\\x -> x"
a0 -> a0
parinfer/benchmark.in を使って並列性効果の確認を行う。
parinfer.hsの buildでつまづいた。
Lex.hs:321:34:
Couldn't match expected type ‘Bool’ with actual type ‘Int#’
In the first argument of ‘(&&)’, namely ‘(offset >=# 0#)’
In the expression: (offset >=# 0#) && (check ==# ord_c)
In the expression:
if (offset >=# 0#) && (check ==# ord_c) then
alexIndexInt16OffAddr alex_table offset
else
alexIndexInt16OffAddr alex_deflt s
Lex.hs:321:53:
Couldn't match expected type ‘Bool’ with actual type ‘Int#’
In the second argument of ‘(&&)’, namely ‘(check ==# ord_c)’
In the expression: (offset >=# 0#) && (check ==# ord_c)
In the expression:
if (offset >=# 0#) && (check ==# ord_c) then
alexIndexInt16OffAddr alex_table offset
else
alexIndexInt16OffAddr alex_deflt s
GHC 7.8.2から 7.10.1にupdateする。
$ ./configure
$ make install
$ ghc --version
The Glorious Glasgow Haskell Compilation System, version 7.10.1
効果なし, ソースを読む気力がでてきたら追記する。
$ cat benchmark.in
id = \x->x ;
a = \f -> f id id ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = \f -> f a a ;
a = let f = a in \x -> x ;
...
5章 Repaを用いたデータ並列プログラミング
5.1 配列、シェイプ、添字
5.2 配列に対する操作
5.3 例:最短路の計算
5.3.1 プログラムの並列化
5.4 畳み込みとシェイプ多相
5.5 例:画像の回転
5.6 まとめ
Repa (regular parallel arrays)は, 並列処理用の配列データ型を提供する。
後述する repa-devilが OSXではインストールに失敗したので, この章の内容はUbuntu 14.04で確認する。
$ sudo cabal install repaRepa_Tutorialを参考に試してみた。
$ ghci
GHCi, version 7.6.3: https://www.haskell.org/ghc/ :? for help
Loading package ghc-prim ... linking ... done.
Loading package integer-gmp ... linking ... done.
Loading package base ... linking ... done.
Prelude> :m +Data.Array.Repa
Prelude Data.Array.Repa> Z
Z
Prelude Data.Array.Repa> :t Z :. 10
Z :. 10 :: Num head => Z :. head
Prelude Data.Array.Repa> :t Z :. (10 :: Int)
Z :. (10 :: Int) :: Z :. Int
Prelude Data.Array.Repa> :t Z :. 10
Z :. 10 :: Num head => Z :. head
Prelude Data.Array.Repa> let x :: Array U DIM3 Int; x = fromListUnboxed (Z :. (3::Int) :. (3::Int) :. (3::Int)) [1..27]
Prelude Data.Array.Repa> :t x
x :: Array U DIM3 Int
Prelude Data.Array.Repa> extent x
((Z :. 3) :. 3) :. 3
Prelude Data.Array.Repa> let sh = extent x
Prelude Data.Array.Repa> rank sh
3
Prelude Data.Array.Repa> size sh
27
Prelude Data.Array.Repa> toUnboxed x
fromList [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27]
Prelude Data.Array.Repa> import qualified Data.Array.Repa as Repa
Prelude Data.Array.Repa Repa> let x = fromListUnboxed (Z :. (3::Int) :. (3::Int)) [1..9]
Prelude Data.Array.Repa Repa> x
AUnboxed ((Z :. 3) :. 3) (fromList [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
Prelude Data.Array.Repa Repa> let y = Repa.map (^2) x
Prelude Data.Array.Repa Repa> y Repa.! (Z :. 0 :. 2)
9.0
Prelude Data.Array.Repa Repa> y Repa.! (Z :. 2 :. 0)
49.0
Prelude Data.Array.Repa Repa> computeP y :: IO (Array U DIM2 Double)
AUnboxed ((Z :. 3) :. 3) (fromList [1.0,4.0,9.0,16.0,25.0,36.0,49.0,64.0,81.0])
Prelude Data.Array.Repa Repa> z <- computeP y :: IO (Array U DIM2 Double)
Prelude Data.Array.Repa Repa> z
AUnboxed ((Z :. 3) :. 3) (fromList [1.0,4.0,9.0,16.0,25.0,36.0,49.0,64.0,81.0])
Prelude Data.Array.Repa Repa> let [w] = computeP y :: [Array U DIM2 Double]
Prelude Data.Array.Repa Repa> w
AUnboxed ((Z :. 3) :. 3) (fromList [1.0,4.0,9.0,16.0,25.0,36.0,49.0,64.0,81.0])
mapが返す D は遅延型を表し配列の計算は行われていないことを示す。computeSによって配列を得ることができる。
配列でなく遅延配列とすることで, 複数の操作の適用に対し中間データの配列を作らないように最適化できる可能性がある。この最適化手法を融合という。
Repaを使って蜜なグラフの最短経路を求める。 -fllvm はLLVMバックエンドを有効にする。
$ ghc -O2 fwdense1 -threaded -fllvm -fforce-recomp -ticky -rtsopts
$ ./fwdense1 500 +RTS -s
1185353928
539,036,780 bytes allocated in the heap
15,131,844 bytes copied during GC
5,563,916 bytes maximum residency (170 sample(s))
422,196 bytes maximum slop
15 MB total memory in use (1 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 401 colls, 0 par 0.03s 0.04s 0.0001s 0.0055s
Gen 1 170 colls, 0 par 0.04s 0.07s 0.0004s 0.0232s
TASKS: 3 (1 bound, 2 peak workers (2 total), using -N1)
SPARKS: 0 (0 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 1.66s ( 2.26s elapsed)
GC time 0.07s ( 0.10s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 1.73s ( 2.37s elapsed)
Alloc rate 324,189,920 bytes per MUT second
Productivity 96.2% of total user, 70.3% of total elapsed
gc_alloc_block_sync: 0
whitehole_spin: 0
gen[0].sync: 0
gen[1].sync: 0
-N2 で試したところ, 6.78s elapsed と遅くなった。
原因は, VirtualBox上で動かしているUbuntu 14.04 に割り当てているCPUコア数が1という凡ミスだった。
/proc/cpuinfo のCPUコアを確認したところ, cpu cores が 1となっている。
情けないが, 並列性の効果の確認は後日にする。
$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 69
model name : Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz
stepping : 1
cpu MHz : 1952.730
cache size : 6144 KB
physical id : 0
siblings : 1
core id : 0
cpu cores : 1
...
devILは, 一般的な画像フォーマットを読み書きできるツール。
repa-devilが OSXではインストールに失敗したので, Ubuntu14.04[5]上で環境を構築してみた。
Ubuntu14.04でも, 依存パッケージの –force-reinstalls が必要と cabalに指摘される 。これは嫌な予感…
$ sudo cabal install repa-devil --force-reinstallsrepa-devil-0.3.2.6がインストールされた。Repaも再度コンパイルされたけど, 大丈夫だろうか。
image型は3次元で, x, y, RGBA情報を持つ。この配列に U でなく F が使われているが, これはCで管理されているメモリに格納されていることを示している。
画像をILモナドのreadImageで読み込んで, 回転させる処理を行い, writeImageを使って書き込む。
$ ghc -O2 rotateimage -threaded -fllvm -fforce-recomp -ticky -rtsopts
$ ./rotateimage 4 haskell.jpeg haskell_rot.jpeg +RTS -s
3,587,812 bytes allocated in the heap
14,244 bytes copied during GC
36,812 bytes maximum residency (2 sample(s))
24,628 bytes maximum slop
1 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 5 colls, 0 par 0.00s 0.00s 0.0001s 0.0002s
Gen 1 2 colls, 0 par 0.00s 0.00s 0.0003s 0.0003s
TASKS: 3 (1 bound, 2 peak workers (2 total), using -N1)
SPARKS: 0 (0 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 0.04s ( 0.09s elapsed)
GC time 0.00s ( 0.00s elapsed)
EXIT time 0.00s ( 0.01s elapsed)
Total time 0.04s ( 0.10s elapsed)
Alloc rate 97,817,233 bytes per MUT second
Productivity 96.6% of total user, 41.7% of total elapsed
gc_alloc_block_sync: 0
whitehole_spin: 0
gen[0].sync: 0
gen[1].sync: 0
回転前と回転後の画像。


6章 AccelerateによるGPUプログラミング
6.1 概要
6.2 配列と添字
6.3 単純なAccelerate計算を実行する
6.4 スカラ配列
6.5 配列に添字でアクセスする
6.6 Accの中で配列を作る
6.7 2つの配列を綴じ合わせる
6.8 定数
6.9 例:最短路問題
6.9.1 GPU上で実行する
6.9.2 CUDAバックエンドのデバッグ
6.10 例:マンデルブロ集合の生成器
前半の最終章。GPUプログラミングに触れる, GPUは汎用CPとは命令セットが異なる。GPUは大量の並列処理装置から成り, 各々は単一のCPUコアより非力なため完全に同一のコードを足並みを揃えて実行する必要がある。GPUコードで条件式を用いるのはSIMDの発散の原因となり, 並列性が急速に失われてしまうようだ。
Haskellの accelerate はGPUプログラミングのための, Embedded DSL である。accelerate-cuda によってGPUコードにコンパイルされGPU上で実行される。
accelerateを使うには, 対象のGPU [4] とCUDA Toolkit, accelerate-cudaが必要になる。インストール方法は Quick Tourに沿ってみる。
結果的にOSXで accelerate-cudaのインストールにつまずいている状態である。
accelerate-cudaはcudaに依存しているがcudaのインストールに失敗する。
CUDAドライバ, CUDA Toolkit 4.0のダウンローダを入手して, インストールする。
インストール後, PATHを通す。
$ export PATH=$PATH:/usr/local/cuda/bin
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib
$ nvcc --version
stackoverflowに習い, 既存のclangを /usr/bin/backupに退避させて, gcc-4.9を /usr/bin/に配置する。
$ sudo mkdir /usr/bin/backup && sudo mv /usr/bin/gcc /usr/bin/g++ /usr/bin/backup
$ sudo ln -s /usr/local/bin/gcc-4.9 /usr/bin/gcc
$ sudo ln -s /usr/local/bin/g++-4.9 /usr/bin/g++
$ gcc -v
$ g++ -v
accelerate-cudaをインストールする。
$ sudo cabal install accelerate-cuda
...
configure: creating ./config.status
config.status: creating cuda.buildinfo
Building cuda-0.6.6.2...
Preprocessing library cuda-0.6.6.2...
dyld: Library not loaded: @rpath/libcudart.dylib
Referenced from: /private/tmp/cabal-tmp-90551/cuda-0.6.6.2/dist/build/Foreign/CUDA/Internal/Offsets_hsc_make
Reason: image not found
running dist/build/Foreign/CUDA/Internal/Offsets_hsc_make failed (exit code -5)
command was: dist/build/Foreign/CUDA/Internal/Offsets_hsc_make >dist/build/Foreign/CUDA/Internal/Offsets.hs
cabal: Error: some packages failed to install:
accelerate-cuda-0.15.0.0 depends on cuda-0.6.6.2 which failed to install.
cuda-0.6.6.2 failed during the building phase. The exception was:
ExitFailure 1
このエラーはこちらと同様, PATHは通っていると思うのだけど。
CUDA Toolkit 5.0 でも試したが同様だった。残念だけど今回は諦めることにした。(解決したら追記する)
[1] Mac OS XにThreadScopeをインストールする(2015年1月版)
[2] 関数プログラミング実践入門 ──簡潔で、正しいコードを書くために (WEB+DB PRESS plus)
[3] 積極評価ではレジスタやメモリへのキャッシュヒットが高まり易い
[4] GPUはIntel HD Graphics 5000 1536 MB
[5] Ubuntu14.04に環境構築した。
$ sudo apt-get install ghc
$ sudo apt-get install cabal-install
$ sudo cabal update
$ sudo cabal install cabal-install