今回は, R による線形回帰分析について書きます。
- 1. 線形回帰分析
- 1-1. 最尤推定
- 1-2. 単回帰分析
- 1-3. 重回帰分析
- 1-4. 重回帰モデルの可視化
- 2. 非線形最小二乗法
環境は OSX 10.9.4で R version 3.1.1 (2014-07-10) です。
1. 線形回帰分析
説明変数を用いて連続量の目的変数を説明する分析を回帰分析と言います。説明変数と目的変数の関係が線形的に示されるモデルを線形モデル, 非線形で示されるモデルを非線形モデルと呼びます。
正規線形回帰モデルではパラメータをデータから最小二乗法 (Ordinary Least Squares; OLS) や最尤推定 (Maximum Likelihood Estimation; MLE) によって推定します。
正規線形モデルにおいて最小二乗推定値と最尤推定値は一致します。線形回帰モデルを拡張した一般化線形モデル (Generalized linear model; GLM) では最尤推定でパラメータ推定を行います。
1-1. 最尤推定
最初に, 最尤推定の仕組みを簡単な例で確認します。
最尤推定は最も尤もらしいパラメータをデータから探します。回帰モデルではパラメータに当たるのが回帰係数です。
例としてくじ引きを考えます。当選確率は未知の状態で 10 回引いたら 4 回当選したとします。当選確率を x, 外れる確率を 1-x とした場合, 対数尤度関数は L(x) = log(x^4 * (1-x)^6) となります。
R で書くと以下となります。
> llf <- function(x) log(x^4 * (1-x)^6)
> exp(llf(0.1))
[1] 5.31441e-05
> exp(llf(0.3))
[1] 0.0009529569
上記から, 仮に x = 0.1 や x = 0.3 とした時に, 10 回引いたら 4 回当選したというデータが得られる確率はそれぞれ 5.31441e-05, 0.0009529569 となります。この 2 つを比較すると x = 0.3 の方が尤もらしい値と言えます。
当選確率 x と対数尤度関数 L(x) の関係を可視化してみます。
> func <- deriv(~ log(x^4 * (1-x)^6), "x", func = T)
> plot(func, xlab = "x", ylab = "L(x)")
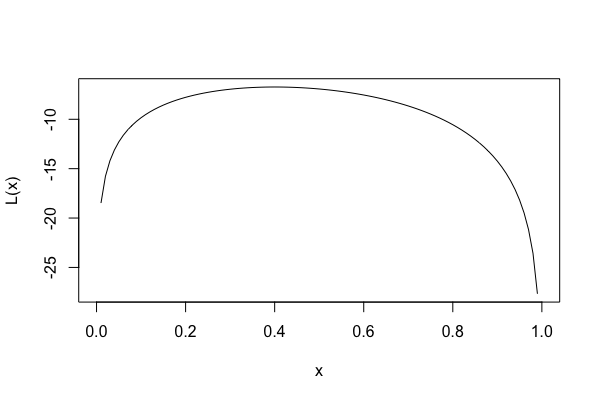
対数尤度関数は 0.4 付近で最大となりそうです。
より具体的に対数尤度関数が最大である値を推定するために stats::optimize() で最適化を行ってみます。
> optimize(llf, c(0, 1), maximum = TRUE)
$maximum
[1] 0.4000015
$objective
[1] -6.730117
0.40 が最も尤もらしい値, 最尤推定値となります。これは直感とも一致していると思います。
stats::optim() は多変量に対応できる stats::optimize() の汎用版です。
> optim(c(0.1), llf, method = "Brent", lower = 0, upper = 1, control = list(fnscale = -1))
$par
[1] 0.4
$value
[1] -6.730117
$counts
function gradient
NA NA
$convergence
[1] 0
$message
NULL
stats::optimize() 同様に 0.4 と求まりました。
今回の例であれば解析的に微分でも解けますが, データサイズが大きくなったり重回帰分析のようにパラメータが増えたりした場合は R などコンピュータにより数値解析を行うのが現実的です。
1-2. 単回帰分析
説明変数が1つの場合は単回帰分析, 複数の場合は重回帰分析となります。
例として cars データセットを使います。cars は Speed (mph), Stopping distance (ft) の2つの変数から成ります。
> tibble::glimpse(cars)
Observations: 50
Variables: 2
$ speed 4, 4, 7, 7, 8, 9, 10, 10, 10, 11, 11, 12, 12, 12, 12, 13,...
$ dist 2, 10, 4, 22, 16, 10, 18, 26, 34, 17, 28, 14, 20, 24, 28,...
csv からデータを読み込みたい場合は utils::read.csv で data.frame として読み込まれます。readr::read_csv を使うと読み込み時に factor が正しく認識され tibble として扱えます。また, 大規模データを高速に読み込みたい場合は data.table::fread を使うと便利です。
stats::lm() で簡単に正規線形回帰モデルを構築できます。
lm(formula, data, subset, weights, na.action,
method = "qr", model = TRUE, x = FALSE, y = FALSE, qr = TRUE,
singular.ok = TRUE, contrasts = NULL, offset, ...)
lm() は内部で最小二乗法でパラメータを推定します。正規線形モデルでは誤差項が正規分布に従うことから最小二乗推定量と最尤推定量は一致します。[1]
base::summary() でモデルの内容を確認できます。
> model.cars <- lm(speed ~ dist, data = cars)
> summary(model.cars)
Call:
lm(formula = speed ~ dist, data = cars)
Residuals:
Min 1Q Median 3Q Max
-7.5293 -2.1550 0.3615 2.4377 6.4179
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.28391 0.87438 9.474 1.44e-12 ***
dist 0.16557 0.01749 9.464 1.49e-12 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.156 on 48 degrees of freedom
Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438
F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
回帰係数に関する推定量の見方です。
- Estimate: 回帰係数の推定値 β
- Std. Error: 標準誤差 se
- t value: t値
- Pr(>|t|): p値 (帰無仮説H0は回帰係数が0)
回帰係数 β の t値 は下記で求まります。

今回の説明変数 dist の t値 は, Estimate / Std. Error = 9.464 です。t値から p値 が計算でき, 1.49e-12 と非常に小さいため dist の回帰係数が 0 であるという帰無仮説H0は棄却できると言えそうです。
モデル評価のひとつとして決定係数があります。
決定係数とは回帰モデルがどの程度データにフィットしているかを表す指標です。R二乗 (R-squared) とも言います。
決定係数または自由度を考慮した自由度調整済み決定係数が 1.0 に近い程, モデルがデータにフィットしていることになります。
ただし, 決定係数はモデル構築に使ったサンプルに対する当てはまりの良さであることに注意です。
決定係数の定義は実は様々あるようですが, Rの base::summary() では 決定係数 = 1 – ( 残差平方和 / 全平方和 )で計算しているようです。
> ?base::summary
...
r.squared R^2
, the ‘fraction of variance explained by the model’,
R^2 = 1 - Sum(R[i]^2) / Sum((y[i]- y*)^2),
where y* is the mean of y[i] if there is an intercept and zero otherwise.
adj.r.squared
the above R^2 statistic ‘adjusted’, penalizing for higher p.
...
summary() による結果の下部には残差や自由度, 決定係数が表示されます。調整済み決定係数 (Adjusted R-squared) は 0.64 となっています。
Residuals:
Residual standard error: 3.156 on 48 degrees of freedom
Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438
また, 回帰係数の信頼区間は stats::confint(cars.res, level = 0.95) で表示でき level で幅を指定できます。予測区間の幅は stats ::predict(cars.lm, interval = “confidence”) で調べられます。
1-3. 重回帰分析
重回帰分析では目的変数に対して複数の説明変数の線形結合で近似するモデルを構築します。
パラメータである偏回帰係数は単回帰分析同様に OLS で求めます。
airquality データセットを使います。
> tibble::glimpse(airquality)
Observations: 153
Variables: 6
$ Ozone 41, 36, 12, 18, NA, 28, 23, 19, 8, NA, 7, 16, 11, 14, 1...
$ Solar.R 190, 118, 149, 313, NA, NA, 299, 99, 19, 194, NA, 256, ...
$ Wind 7.4, 8.0, 12.6, 11.5, 14.3, 14.9, 8.6, 13.8, 20.1, 8.6,...
$ Temp 67, 72, 74, 62, 56, 66, 65, 59, 61, 69, 74, 69, 66, 68,...
$ Month 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5...
$ Day 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, ...
各変数間の関係を散布図で確認します。また, 相関行列 (ピアソンの積率相関係数) を確認します。
pairs(airquality[,1:4],pch = 21, bg = "red", cex = 1)
相関係数により変数間の関係の強さがわかりますが, 相関関係は必ずしも因果関係を表しているわけではないので注意が必要です。[2] また, 関係性の指標はピアソンの相関係数以外にもあり, 変数の尺度によっても用いるべき指標は異なってきます。
lm() で重回帰分析を行う場合, 説明変数を formula に `+` 演算子で追加するだけです。
> model.air <- lm(Ozone ~ Solar.R + Wind + Temp, data = airquality)
> summary(model.air)
Call:
lm(formula = Ozone ~ Solar.R + Wind + Temp, data = airquality)
Residuals:
Min 1Q Median 3Q Max
-40.485 -14.219 -3.551 10.097 95.619
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -64.34208 23.05472 -2.791 0.00623 **
Solar.R 0.05982 0.02319 2.580 0.01124 *
Wind -3.33359 0.65441 -5.094 1.52e-06 ***
Temp 1.65209 0.25353 6.516 2.42e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 21.18 on 107 degrees of freedom
(42 observations deleted due to missingness)
Multiple R-squared: 0.6059, Adjusted R-squared: 0.5948
F-statistic: 54.83 on 3 and 107 DF, p-value: < 2.2e-16
一般的に重回帰分析では 多重共線性 (multicollinearity) に気をつける必要があります。重回帰分析で回帰係数を求める時に偏微分を行います。
これは注目している説明変数以外の説明変数の値を固定した上で, 注目している説明変数の値を変化させ目的変数との関係性をみていく操作と考えることができます。
この時, 説明変数間に相関が高い関係があると固定の操作の効果が薄くなり, 上手く回帰係数が求められなくなります。これを多重共線性といいます。
また, 疑似相関 [3] が疑われる場合は 偏相関係数 を用いて確認する方法があります。
ppcor::pcor() で, 注目している2変数間以外の変数の影響を取り除いた偏相関行列を確認できます。
> air <- na.omit(airquality)
> ppcor::pcor(air)$estimate
Ozone Solar.R Wind Temp Month
Ozone 1.0000000 0.20505146 -0.44897864 0.55975584 -0.19236023
Solar.R 0.2050515 1.00000000 0.11427512 0.14942920 -0.17190775
Wind -0.4489786 0.11427512 1.00000000 -0.07988093 -0.07467615
Temp 0.5597558 0.14942920 -0.07988093 1.00000000 0.43771581
Month -0.1923602 -0.17190775 -0.07467615 0.43771581 1.00000000
Day 0.1155939 -0.04728812 0.05413314 -0.12748877 0.04833785
Day
Ozone 0.11559389
Solar.R -0.04728812
Wind 0.05413314
Temp -0.12748877
Month 0.04833785
Day 1.00000000
多重共線性の指標として, 分散拡大係数 (VIF) があり car::vif() で確認できます。
ヒューリスティックではあるかもしれませんが, VIF が 10 を超えると危険なようです。
> car::vif(model.air)
Solar.R Wind Temp
1.095253 1.329070 1.431367
変数選択時に, 科学的理論やドメイン知識によって適当だと考えられる変数を指定する 変数指定法 が用いられることがあります。
モデル選択基準としては AIC (Akaike’s An Information Criterion) を見ておくと良さそうです。また, 説明変数が多いような高次元のデータでは, L1 / L2正則化を検討するのも良いと思います。
得られた回帰モデルの確認として, 回帰診断図 (diagnostic plots) があります。
par(mfrow = c(2,2))
plot(model.air)
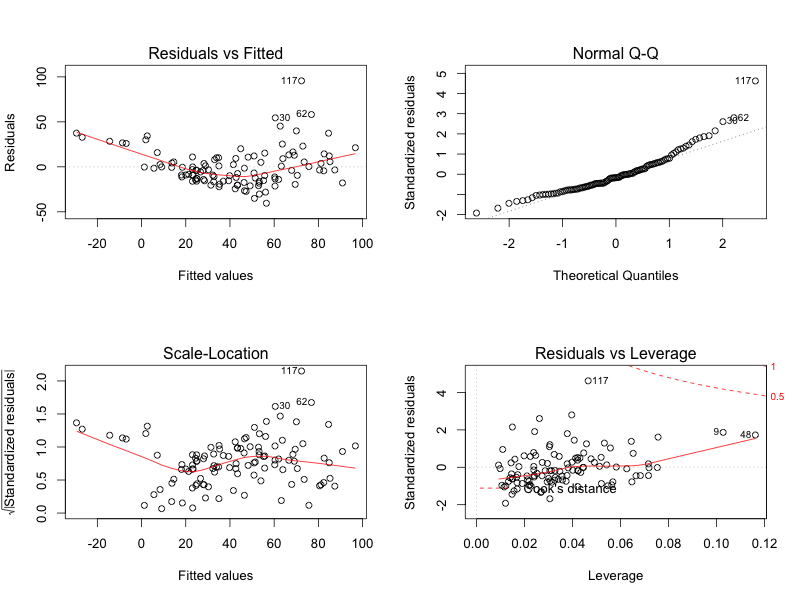
表示された4つのグラフの概要は下記です。
- x軸が予測値, y軸が残差のプロット: 水平な程良い。
- Q-Q (Quantile-Quantile) プロット: 正規性の確認を行う。
- 残差の平方根のプロット: 残差の変動を確認する。
- Cook’S 距離: 影響度が大きいデータの検出を行う。
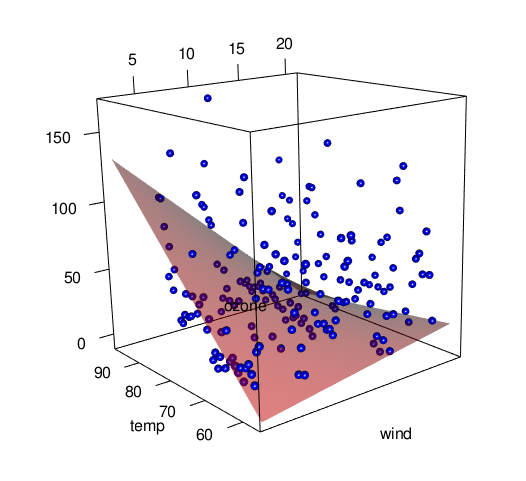
1-4. 重回帰モデルの可視化
重回帰モデルを {rgl} で可視化してみます。説明変数を Wind, Temp の2つに変更しています。
可視化の前にでデータの範囲を確認します。
> sapply(air, range)
Ozone Solar.R Wind Temp Month Day
[1,] 1 7 2.3 57 5 1
[2,] 168 334 20.7 97 9 31
rgl::plot3d() で観測データをplotして, rgl::surface3d() で重回帰モデルで予測値を面で重ねてプロットします。
rgl::writeWebGL() で Draggable に操作できる WebGL を用いた HTML / JavaScript が生成されます。
x1 <- air$Wind
x2 <- air$Temp
air.lm <- lm(air$Ozone ~ (x1 + x2)^2, data = air)
summary(air.lm)
sapply(air, range)
x1 <- seq(from = 2.3, to = 20.7, by = 0.1)
x2 <- seq(from = 57, to = 97, by = 1)
air.sur <- outer(X = x1, Y = x2, FUN = function(x1, x2) {
predict(air.lm, newdata = data.frame(x1 = x1, x2 = x2))
})
rgl::plot3d(x1, x2, air$Ozone, xlab = "wind", ylab = "temp", zlab = "ozone",
size = 1, type = "s", col = "blue")
rgl::surface3d(x = x1, y = x2, z = air.sur, col = "red", alpha = 0.5)
writeWebGL(width = 500, height = 550)
2. 非線形最小二乗法
非線形最小二乗法を扱う stats::nls() は stats::lm() と異なり, formula に目的変数と説明変数間の関係を意味する関数を書きます。
nls(formula, data, start, control, algorithm,
trace, subset, weights, na.action, model,
lower, upper, ...)
Simple nonlinear least squares curve fitting in Rを参考にしました。
xdata <- c(-2, -1.64, -1.33, -0.7, 0, 0.45, 1.2, 1.64, 2.32, 2.9)
ydata <- c(0.699369, 0.700462, 0.695354, 1.03905, 1.97389, 2.41143, 1.91091,
0.919576, -0.730975, -1.42001)
# look at it
plot(xdata, ydata)
# some starting values
p1 <- 1
p2 <- 0.2
# do the fit
fit <- nls(ydata ~ p1 * cos(p2 * xdata) + p2 * sin(p1 * xdata), start = list(p1 = p1, p2 = p2))
# summarise
summary(fit)
new <- data.frame(xdata = seq(min(xdata), max(xdata), len = 200))
lines(new$xdata, predict(fit, newdata = new))
stats::nls() でもパラメータを目的変数と説明変数の実測値と推測値の差を最小にする最小2乗法で推測しますが, 線形回帰分析と比較して計算が少し難しくなるため上手くパラメータを出せずに失敗する場合があります。
おわりに
統計・機械学習のシステム化まで想定する場合, NumPy, Pandas, scikit-learn などのライブラリ群が豊富な Python が向いている印象です。一方, アドホックな分析には R, 速度を求める場合は Julia という選択肢があると思います。また, 統計・機械学習以外の FFT など信号処理や画像処理など科学技術計算を行う場合は, アルゴリズムが充実している MATLAB を使うのが良いと思います。
最後にRのデータ構造に触れたいと思います。R では Vector と Matrix, Array は同じ型でしか代入できません。一方で DataFrame や List は異なるデータ型を代入できます。同じ型であれば Vector や Matrix を使った方が高速です。ただし, Vector ではある型と NA を混在させることはできますが, NULL を混ぜた場合は NULL は無視される点には注意が必要です。Matrix と Array の違いは, Matrix が二次元なのに対して Array はそれ以上の次元を扱うことができます。
[1] 最小二乗法と最尤法
[2] 因果関係を示したい場合には, 統計的因果推論による様々な方法があるが最終的な判断は注意すべき点が多い。
[3] 例えば, “高血圧の人ほど年収が高い”という結果があるとする。一般に, 年齢が高いほど高血圧である可能性が高く, 一方で年齢が高いほど年収が高いことは容易に考えれる。第三の変数 (年齢)によって, 本来は直接関連していない関係性を示すことを疑似相関と呼ばれる。